Liên hệ nhanh
Vui lòng điền thông tin form bên dưới để chúng tôi liên hệ nhanh với quý khách!
Vui lòng điền thông tin form bên dưới để chúng tôi liên hệ nhanh với quý khách!
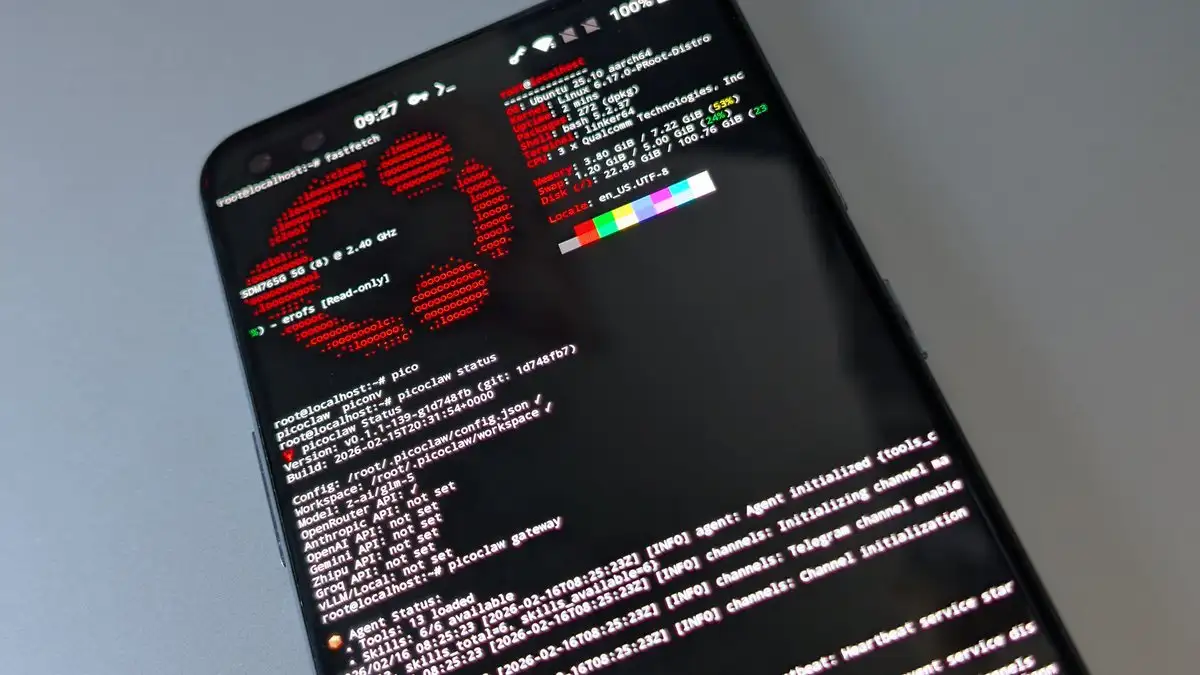
Nội dung Việc tái sử dụng điện thoại Android cũ thành trạm điều khiển [...]

Nội dung OpenClaw là một trợ lý AI cá nhân. Nó kết nối các nền [...]

Nội dung Trước đây, việc tạo hình ảnh thường gắn liền với các API [...]
Nội dung Hệ thống quản lý kho đơn giản với trình tạo mã QR. NocoDB tự [...]
Nội dung Trong quá trình phát triển hàng ngày, vấn đề gửi vòng lặp dữ [...]

Nội dung API (Giao diện lập trình ứng dụng) là cầu nối cho phép các ứng [...]

Nội dung Odoo 19 vừa ra mắt. Tôi đã cài đặt nó trên máy Mac [...]
Nội dung Tôi đã viết CSS trong nhiều năm. Tôi sử dụng Flexbox và Grid [...]

Nội dung JavaScript đang phát triển rất nhanh chóng. Việc nắm vững các phím tắt [...]

Nội dung Vào năm 2025, Trí tuệ Nhân tạo (AI) không còn là công cụ [...]