Liên hệ nhanh
Vui lòng điền thông tin form bên dưới để chúng tôi liên hệ nhanh với quý khách!
Vui lòng điền thông tin form bên dưới để chúng tôi liên hệ nhanh với quý khách!

Nội dung Hệ thống AI không thất bại vì mô hình yếu, mà thất [...]

Nội dung Xây dựng vLLM-MLX – một framework sử dụng MLX của Apple để tăng [...]
Nội dung Một trợ lý phỏng vấn hoạt động mà không cần gọi điện [...]

Nội dung Đây là 8 mẫu thiết kế kỹ thuật dữ liệu mà mọi kiến [...]
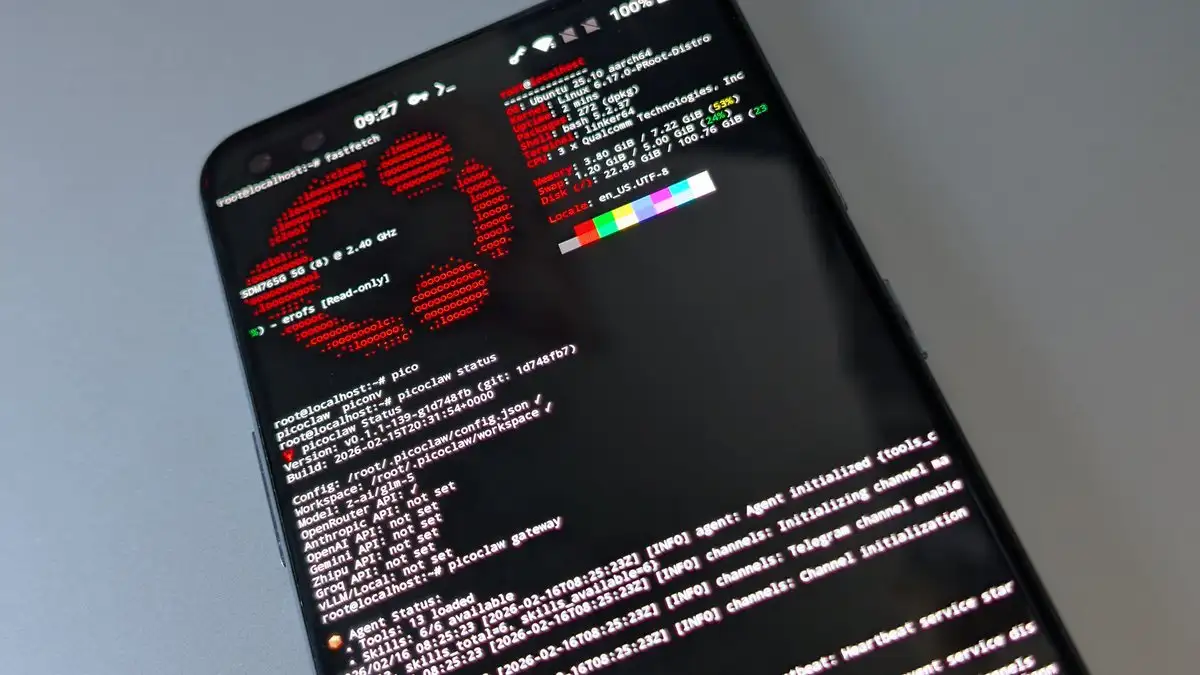
Nội dung Việc tái sử dụng điện thoại Android cũ thành trạm điều khiển [...]

Nội dung OpenClaw là một trợ lý AI cá nhân. Nó kết nối các nền [...]

Nội dung Trước đây, việc tạo hình ảnh thường gắn liền với các API [...]
Nội dung Hệ thống quản lý kho đơn giản với trình tạo mã QR. NocoDB tự [...]
Nội dung Trong quá trình phát triển hàng ngày, vấn đề gửi vòng lặp dữ [...]

Nội dung API (Giao diện lập trình ứng dụng) là cầu nối cho phép các ứng [...]