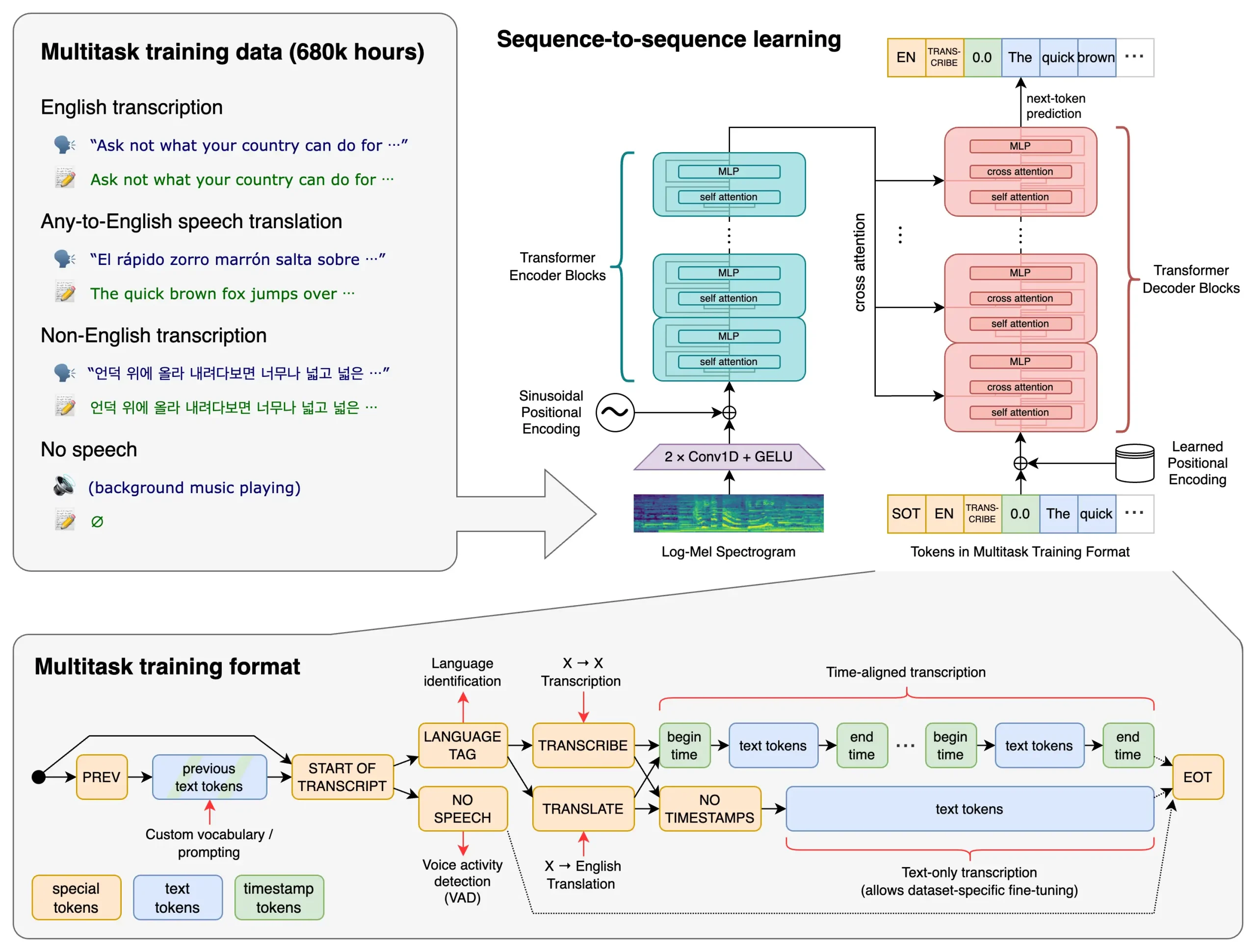
Whisper là một mô hình nhận dạng giọng nói đa năng. Nó được đào tạo trên một tập dữ liệu âm thanh lớn, đa dạng và cũng là một mô hình đa nhiệm, có thể thực hiện nhận dạng giọng nói đa ngôn ngữ, dịch giọng nói và nhận dạng ngôn ngữ.
Độ mạnh mẽ của PhoWhisper đạt được thông qua việc tinh chỉnhWhisper đa ngôn ngữ trên bộ dữ liệu 844 giờ bao gồm nhiều giọng Việt khác nhau. Nghiên cứu thực nghiệm của chúng tôi chứng minh hiệu suất vượt trội của PhoWhisper trên các bộ dữ liệu ASR tiếng Việt chuẩn.
ASR: //huggingface.co/vinai/PhoWhisper-tiny
Ứng dụng //github.com/xinnan-tech/xiaozhi-esp32-server/blob/main/README_vi.md
Dùng Whisper
Chúng tôi đã sử dụng Python 3.9.9 và PyTorch 1.10.1 để huấn luyện và kiểm tra các mô hình, nhưng cơ sở mã dự kiến sẽ tương thích với Python 3.8-3.11 và các phiên bản PyTorch gần đây. Cơ sở mã cũng phụ thuộc vào một số gói Python, đáng chú ý nhất là tiktoken của OpenAI nhờ khả năng triển khai tokenizer nhanh chóng. Bạn có thể tải xuống và cài đặt (hoặc cập nhật lên) phiên bản mới nhất của Whisper bằng lệnh sau:
pip install -U openai-whisper
Ngoài ra, lệnh sau sẽ kéo và cài đặt bản cam kết mới nhất từ kho lưu trữ này, cùng với các phụ thuộc Python của nó:
pip install git+//github.com/openai/whisper.git
Để cập nhật gói lên phiên bản mới nhất của kho lưu trữ này, vui lòng chạy:
pip install –upgrade –no-deps –force-reinstall git+//github.com/openai/whisper.git
Nó cũng yêu cầu phải cài đặt công cụ dòng lệnh ffmpegtrên hệ thống của bạn, có sẵn trong hầu hết các trình quản lý gói:
# on MacOS using Homebrew (//brew.sh/)
brew install ffmpeg
Cài ffmpeg vào virtual environment:
# Kích hoạt venv
source /Users/mt/venv/bin/activate
# Tạo symlink trong venv/bin
ln -sf /opt/homebrew/bin/ffmpeg “$VIRTUAL_ENV/bin/ffmpeg”
ln -sf /opt/homebrew/bin/ffprobe “$VIRTUAL_ENV/bin/ffprobe”
Bây giờ trong venv, ffmpeg sẽ luôn khả dụng
Bạn cũng có thể cần rustcài đặt, phòng trường hợp tiktoken không cung cấp bánh xe dựng sẵn cho nền tảng của bạn. Nếu bạn gặp lỗi cài đặt trong khi thực pip installhiện lệnh trên, vui lòng làm theo trang Bắt đầu để cài đặt môi trường phát triển Rust. Ngoài ra, bạn có thể cần cấu hình PATHbiến môi trường, ví dụ export PATH=”$HOME/.cargo/bin:$PATH”: . Nếu quá trình cài đặt không thành công với No module named ‘setuptools_rust’, bạn cần cài đặt setuptools_rust, ví dụ: bằng cách chạy:
pip install setuptools-rust
Lệnh sau sẽ phiên âm giọng nói thành tệp âm thanh bằng cách sử dụng turbomô hình:
whisper audio.flac audio.mp3 audio.wav –model turbo
Cài đặt mặc định (chọn turbomô hình) hoạt động tốt khi phiên âm tiếng Anh. Tuy nhiên, mô turbohình không được huấn luyện cho các tác vụ dịch thuật . Nếu bạn cần dịch lời nói không phải tiếng Anh sang tiếng Anh , hãy sử dụng một trong các mô hình đa ngôn ngữ ( tiny, base, small, medium, large) thay vì turbo.
Ví dụ, để phiên âm một tệp âm thanh có chứa giọng nói không phải tiếng Anh, bạn có thể chỉ định ngôn ngữ:
whisper japanese.wav –language Japanese
whisper output.wav –language Vietnamese
whisper long.wav –language Vietnamese –task transcribe –fp16 False
Để dịch lời nói sang tiếng Anh, hãy sử dụng:
whisper japanese.wav –model medium –language Japanese –task translate
Lưu ý: Mô hình turbo sẽ trả về ngôn ngữ gốc ngay cả khi –task translate được chỉ định. Sử dụng medium hoặc large để có kết quả dịch tốt nhất.
Chạy lệnh sau để xem tất cả các tùy chọn có sẵn: whisper –help
Phiên âm cũng có thể được thực hiện trong Python:
import whisper
model = whisper.load_model(“turbo”)
result = model.transcribe(“audio.mp3”)
print(result[“text”])
Về mặt nội bộ, transcribe() phương pháp này đọc toàn bộ tệp và xử lý âm thanh bằng cửa sổ trượt 30 giây, thực hiện dự đoán tự hồi quy theo trình tự trên mỗi cửa sổ.
Dùng PhoWhisper-tiny chạy trên Mac
Vì model nhỏ (tiny) ~39M tham số, tương đối nhẹ, nên chạy trên CPU vẫn ổn. File âm thanh nên có tần số lấy mẫu 16 kHz (16 000 Hz)
Tạo môi trường ảo (virtualenv) để tránh xung đột.
python3.13 -m venv venv
source venv/bin/activate
Cài các thư viện cần thiết:
pip install –upgrade pip
pip install transformers datasets soundfile torch
— Lưu ý: trên Mac M4 bạn nên cài phiên bản torch tương thích với ARM / M1/M2/M4. Ví dụ:
pip install torch torchvision torchaudio –index-url //download.pytorch.org/whl/cpu
nếu bạn không có GPU/Metal backend. Cài thêm ffmpeg nếu cần (ví dụ để xử lý file âm thanh đa dạng định dạng)
brew install ffmpeg
Trong issues của PhoWhisper có người gặp lỗi “ffmpeg was not found but is required to load audio files from filename” khi dùng pipeline.
Tạo file transcribe.py:
from transformers import pipeline
import torch
model_id = “vinai/PhoWhisper-tiny”
device = 0 if torch.backends.mps.is_available() else -1
print(“Using device:”, device)
transcriber = pipeline(
“automatic-speech-recognition”,
model=model_id,
device=device
)
audio_file = “audio_vi_16k.wav” # đảm bảo 16kHz
result = transcriber(audio_file)
print(“Transcription:”, result[“text”])
Chạy: python3 transcribe.py
Kết quả sẽ in ra đoạn transcription tiếng Việt từ file âm thanh. Nhưng lỗi TorchCodec không load được khi chạy pipeline ASR của PhoWhisper trên Mac M4 + Python 3.13 + PyTorch nightly (2.10.0.dev…). Đây là lỗi phổ biến vì TorchCodec chưa hỗ trợ PyTorch nightly mới + Python 3.13 + ARM, và pipeline ASR của transformers (từ v4.40 trở lên) mặc định tự import torchcodec → fail.
Nên dùng code bypass TorchCodec (bỏ pipeline, dùng model thủ công). file audio về 16 kHz trước khi load.
Giờ tạo script test.py để: Nhận đường dẫn file audio từ dòng lệnh: python test.py audio.wav Trong đó tự động resample về 16kHz (tránh lỗi sampling rate 24kHz/48kHz), chuyển mono. Vẫn dùng pipeline ASR của PhoWhisper-tiny. Không sử dụng TorchCodec. Xuất JSON. Tính thời gian xử lý tổng + thời gian cho mỗi đoạn (nếu chia nhỏ). Chia nhỏ file dài thành các đoạn theo số giây (mặc định: 30s/đoạn). Tự động resample 16 kHz, chuyển mono. Xóa file tạm sau khi chạy.
import sys
import os
import json
import time
import uuid
import soundfile as sf
import numpy as np
from scipy.signal import resample_poly
from transformers import pipeline
# ==============================
# 1. Helper: resample → 16kHz
# ==============================
def ensure_16k_mono(audio, sr):
# Stereo → mono
if audio.ndim > 1:
audio = np.mean(audio, axis=1)
# Resample nếu không phải 16k
if sr != 16000:
print(f”[INFO] Resampling {sr} Hz → 16000 Hz”)
audio = resample_poly(audio, 16000, sr)
sr = 16000
return audio, sr
# ==============================
# 2. Helper: chia nhỏ file audio
# ==============================
def split_audio(audio, sr, chunk_seconds=30):
chunk_len = chunk_seconds * sr
chunks = []
for i in range(0, len(audio), chunk_len):
chunk = audio[i:i + chunk_len]
if len(chunk) > 0:
chunks.append(chunk)
return chunks
# ==============================
# 3. Main
# ==============================
def main():
if len(sys.argv) < 2:
print(“Usage: python test.py <audio_file.wav>”)
sys.exit(1)
input_path = sys.argv[1]
# ==============================
# Load & chuẩn hóa âm thanh
# ==============================
print(f”[INFO] Loading: {input_path}”)
audio, sr = sf.read(input_path)
audio, sr = ensure_16k_mono(audio, sr)
# ==============================
# 4. Chia nhỏ audio
# ==============================
CHUNK_SECONDS = 30 # thay đổi nếu muốn
chunks = split_audio(audio, sr, CHUNK_SECONDS)
print(f”[INFO] File được chia thành {len(chunks)} đoạn ({CHUNK_SECONDS}s mỗi đoạn)”)
# ==============================
# 5. Load model ASR
# ==============================
print(“[INFO] Loading PhoWhisper model…”)
asr = pipeline(“automatic-speech-recognition”,model=”vinai/PhoWhisper-tiny”)
results = [] total_start = time.time()
# ==============================
# 6. Xử lý từng đoạn
# ==============================
for idx, chunk in enumerate(chunks):
print(f”[INFO] → Processing chunk {idx+1}/{len(chunks)}”)
temp_name = f”_temp_{uuid.uuid4().hex}.wav”
sf.write(temp_name, chunk, sr)
t0 = time.time()
out = asr(temp_name)
t1 = time.time()
# Lưu kết quả
results.append({“chunk_index”: idx,”start_time_sec”: idx * CHUNK_SECONDS,”end_time_sec”: (idx + 1) * CHUNK_SECONDS,”processing_time_sec”: round(t1 – t0, 3),”text”: out[“text”],})
# Xóa file tạm
os.remove(temp_name)
total_end = time.time()
# ==============================
# 7. Xuất JSON
# ==============================
output_json = {“input_file”: input_path,”total_chunks”: len(results),”total_processing_time_sec”: round(total_end – total_start, 3),”chunks”: results,
“full_text”: ” “.join(r[“text”] for r in results)}
out_file = “transcription.json”
with open(out_file, “w”, encoding=”utf-8″) as f:
json.dump(output_json, f, ensure_ascii=False, indent=2)
print(“\n===== DONE =====”)
print(f”JSON saved → {out_file}”)
print(“================”)
print(“Full text:”)
print(output_json[“full_text”])
print(“================”)
if __name__ == “__main__”:
main()
HƯỚNG DẪN CHẠY python test.py my_audio.wav
JSON OUTPUT
{
“input_file”: “audio.wav”,
“total_chunks”: 3,
“total_processing_time_sec”: 8.234,
“chunks”: [
{
“chunk_index”: 0,
“start_time_sec”: 0,
“end_time_sec”: 30,
“processing_time_sec”: 2.121,
“text”: “xin chào đây là đoạn đầu”
},
…
],
“full_text”: “xin chào đây là đoạn đầu … ”
}
Bài viết liên quan: