Khái niệm cơ sở dữ liệu vector (vector database) đã được ứng dụng hàng ngày. Người dùng đang hưởng lợi từ ý tưởng này. Ví dụ, Khi bạn tìm kiếm trên Google, khi Netflix gợi ý một bộ phim bạn thực sự thích, hay khi Spotify gợi ý một bài hát phù hợp với tâm trạng của bạn — đó chính là tìm kiếm vector đang hoạt động âm thầm đằng sau hậu trường.
Hạn chế của Cơ sở Dữ liệu Truyền thống
Các cơ sở dữ liệu quan hệ (relational databases) như MySQL hoặc PostgreSQL thường được sử dụng ban đầu. Chúng rất tốt cho việc quản lý dữ liệu dạng bảng như khách hàng, sản phẩm, hoặc hóa đơn. Chúng hoạt động nhanh và đáng tin cậy.
Tuy nhiên, hạn chế là chúng chỉ khớp các giá trị chính xác. Nếu lưu trữ từ “car” (xe hơi) và tìm kiếm từ “automobile” (ô tô), cơ sở dữ liệu sẽ không trả về kết quả nào (zero rows).
Máy móc bị giới hạn bởi từ ngữ chính xác, trong khi con người thì không. Vì vậy, cần một phương pháp mới để lưu trữ và tìm kiếm dữ liệu dựa trên ý nghĩa, không chỉ khớp văn bản. Đây là vai trò của cơ sở dữ liệu vector.
Vector là gì?
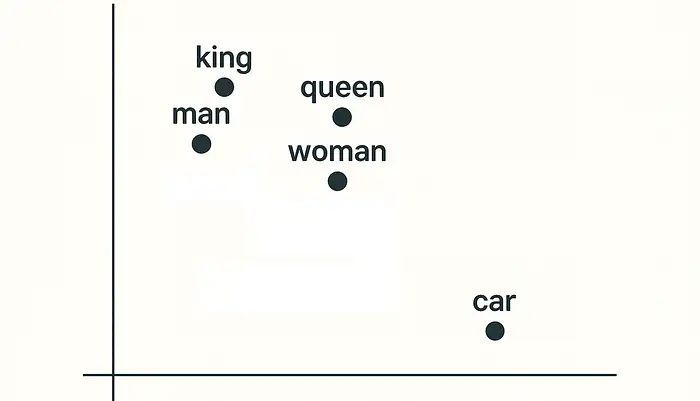
Trong bối cảnh này, vector là một danh sách các con số. Các con số này đại diện cho một đối tượng, bao gồm từ, câu, hình ảnh, hoặc đoạn âm thanh.
Ví dụ về Vector:
- Vector cho từ “king” (vua) có thể là [0.25, 0.88, -0.47, 0.91].
- Vector cho từ “queen” (hoàng hậu) có thể là [0.28, 0.90, -0.45, 0.92].
Sự gần nhau của các vector này cho thấy chúng mang ý nghĩa tương tự. Vector cho từ “car” (xe hơi) sẽ khác biệt hoàn toàn và nằm xa trong “không gian ý nghĩa” vô hình. Điều này tương tự như các thành phố trên bản đồ: “king” và “queen” gần nhau, nhưng “king” và “car” thì không.
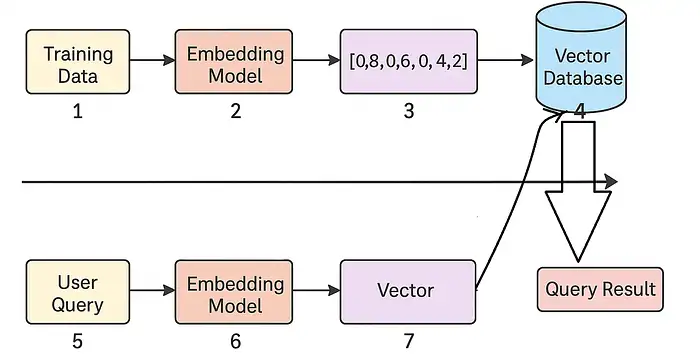
Nguồn gốc của Vector (Embedding Models)
Các vector không được viết thủ công. Chúng được tạo ra bởi các mô hình học máy (machine learning models). Các mô hình tạo vector này được gọi là mô hình nhúng (embedding models). Chức năng của chúng là dịch dữ liệu thô thành các con số. Dữ liệu thô có thể là văn bản, âm thanh, hình ảnh, hoặc video.
Quy trình tạo Vector (Pipeline):
- Cung cấp dữ liệu đầu vào (ví dụ: câu “I love pizza”).
- Mô hình nhúng tạo ra một vector (ví dụ: [0.12, -0.33, 0.95, …]).
- Vector được tạo ra sẽ được lưu trữ trong cơ sở dữ liệu vector.
Mỗi mảnh dữ liệu (văn bản, hình ảnh, hoặc âm thanh) giờ đây có một “dấu vân tay ý nghĩa” bằng các con số, đó chính là vector.

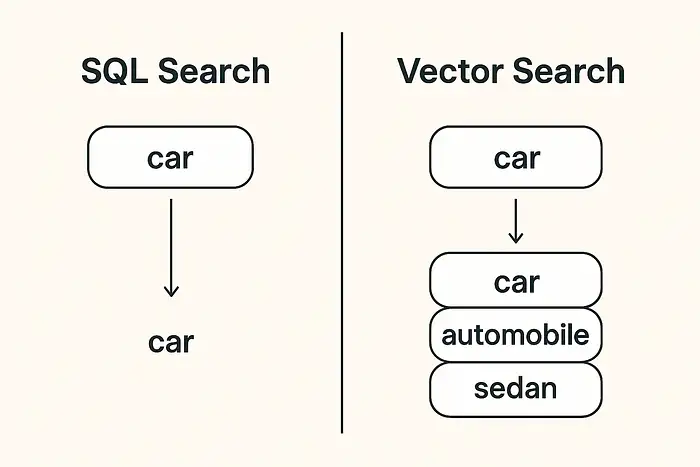
Tìm kiếm từ khóa so với Tìm kiếm ý nghĩa
Giả sử xây dựng một ứng dụng công thức nấu ăn.
Người dùng tìm kiếm “pasta with cheese” (mì ống với phô mai).
Cơ sở dữ liệu SQL thông thường chỉ tìm thấy các công thức chứa chính xác các từ đó.
Các công thức như “fried spaghetti” (spaghetti chiên) hoặc “macaroni with cheddar” (macaroni với phô mai cheddar) sẽ bị bỏ qua. SQL không trả về kết quả vì nó chỉ khớp hoàn hảo dữ liệu đầu vào với dữ liệu đã lưu trữ.
Ngược lại, cơ sở dữ liệu vector nhận ra bức tranh lớn hơn. Nó hiểu parmesan là phô mai, spaghetti là mì ống, và macaroni cùng loại. Tìm kiếm vector hoạt động như bộ não con người: nó tìm các công thức có cùng ý nghĩa, không chỉ cùng cách viết.
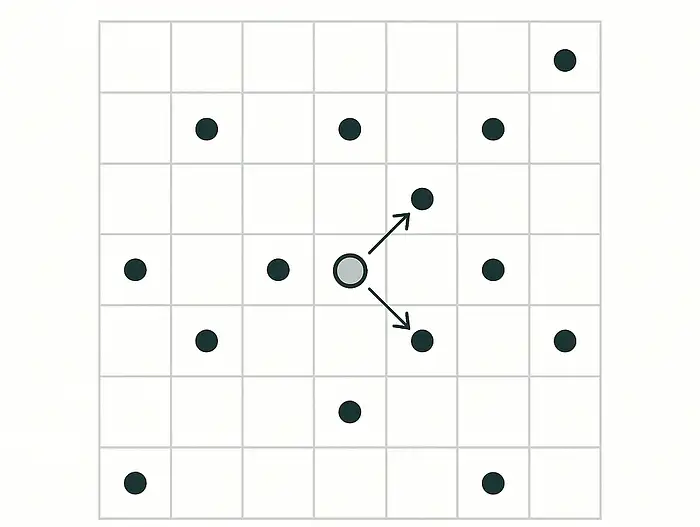
Tối ưu hóa tốc độ tìm kiếm
Việc so sánh tất cả 10 triệu vector theo kiểu vét cạn (brute force) là quá chậm. Trong SQL, việc lập chỉ mục (indexing) thường dùng B-Tree hoặc Hash để tăng tốc. Trong NoSQL, người ta dùng chỉ mục thứ cấp (Secondary index) hoặc chỉ mục phức hợp (compound index).
Đối với cơ sở dữ liệu vector, chúng sử dụng các kỹ thuật như tìm kiếm Láng giềng gần nhất Xấp xỉ (Approximate Nearest Neighbor – ANN).
ANN xây dựng các cấu trúc (đồ thị hoặc cây) cho phép nhảy trực tiếp đến các kết quả có khả năng khớp. Điều này giúp tiết kiệm thời gian bằng cách không cần kiểm tra mọi vector.
Hãy tưởng tượng bạn đang ở một bữa tiệc và cố gắng tìm người bạn thân nhất của mình. Thay vì quét từng khuôn mặt, bạn đi thẳng đến nhóm bạn thường tụ tập. Tiết kiệm thời gian. ANN cũng làm điều tương tự — nó xây dựng các cấu trúc (biểu đồ hoặc cây) để có thể nhảy thẳng đến các kết quả trùng khớp có khả năng xảy ra mà không cần kiểm tra tất cả.
Các Cơ sở Dữ liệu Vector nào
- Pinecone: Được quản lý hoàn toàn (fully managed), loại bỏ lo lắng về cơ sở hạ tầng.
- Weaviate: Mã nguồn mở (open source), tài liệu tốt, phù hợp cho người mới bắt đầu.
- Milvus: Được sử dụng nhiều trong các hệ thống sản xuất (production systems), được xây dựng để mở rộng quy mô.
- FAISS: Là một thư viện từ Meta, cấp độ thấp hơn (low-level), tuyệt vời để tìm hiểu cơ chế hoạt động.
Đối với dự án phụ (side project), Pinecone hoặc Weaviate ít phức tạp hơn.
FAISS tốt cho việc tìm hiểu toán học đằng sau và thân thiện với CPU.
Ví dụ về Đề xuất Phim
Giả sử xây dựng ứng dụng đề xuất phim. Các mô tả phim (tóm tắt cốt truyện, thể loại, đánh giá) được nhúng thành vector. Người dùng tìm kiếm: “sci-fi movie about space travel and family” (phim khoa học viễn tưởng về du hành không gian và gia đình).
Truy vấn này được chuyển đổi thành một vector.
Cơ sở dữ liệu tìm kiếm các vector phim gần với vector truy vấn đó.
Kết quả trả về là: Interstellar, The Martian, Gravity.
Người dùng không gõ chính xác các tên phim này.
Hệ thống vẫn tìm thấy chúng (tương tự như đề xuất của Netflix hoặc tìm kiếm video trên Youtube).
Điều này xảy ra vì các vector đã nắm bắt được ý tưởng “khoa học viễn tưởng + không gian + chủ đề gia đình.”
Ứng dụng Thực tế của Tìm kiếm Vector
- Chatbots: Bot tìm kiếm cơ sở dữ liệu vector để tìm các phần tài liệu liên quan của công ty để trả lời.
- Công cụ Tìm kiếm: Google hiện giải thích ý định của người dùng, không chỉ khớp từ khóa.
- Mua sắm: Amazon đề xuất các mặt hàng “tương tự” về mặt ý nghĩa với những gì đã xem.
- Phát trực tuyến (Streaming): Spotify gợi ý các bài hát phù hợp với tâm trạng; YouTube xếp hàng các video có khả năng được xem tiếp theo.
- Bảo mật (Security): Các ngân hàng kiểm tra giao dịch hiện tại có tương tự các giao dịch “bình thường” trong quá khứ hay khác biệt đáng ngờ.
Tìm kiếm vector đã trở nên phổ biến ở khắp mọi nơi.
Lộ trình cho Người mới bắt đầu
- Thử nghiệm Embeddings: Sử dụng API nhúng của OpenAI (rẻ và dễ dàng); nhập cụm từ và quan sát các vector.
- Chạy FAISS cục bộ: Lưu trữ vài trăm vector, tìm kiếm chúng và xem kết quả.
- Thử tùy chọn được lưu trữ (Hosted option): Pinecone và Weaviate đều có tầng dịch vụ miễn phí (free tier).
- Xây dựng ứng dụng nhỏ: Có thể là công cụ tìm kiếm ghi chú, tìm công thức, hoặc chatbot cá nhân.
Nên bắt đầu từ quy mô nhỏ, sau đó phát triển.
Lời khuyên bổ sung
- Không nên sa đà vào các công thức toán học ngay lập tức.
- Chỉ cần 50 ví dụ là đủ để cảm nhận cách tìm kiếm vector hoạt động.
- Sử dụng công cụ để trực quan hóa (Visualize) các vector trong không gian 2D để thấy các cụm (clusters) hình thành tự nhiên.
- Để tìm hiểu sâu hơn, nên nghiên cứu về độ tương đồng Cosine (cosine similarity).
- Độ tương đồng Cosine là thước đo khoảng cách (distance measure) được sử dụng phổ biến nhất.
Cơ sở dữ liệu vector là một cách để lưu trữ ý nghĩa. Chúng không thay thế cơ sở dữ liệu SQL hoặc NoSQL hiện có. Chúng hoạt động song song, bổ sung thêm một khả năng mới: sự thấu hiểu (understanding).
Tham khảo: medium.com
Bài viết liên quan: