Trong bài viết này, chúng ta sẽ xây dựng một chatbot Agentic RAG (Retrieval-Augmented Generation) hoàn chỉnh bằng cách sử dụng n8n làm trình điều phối, PostgreSQL 16 + pgvector làm kho lưu trữ vector, OpenAI cho embeddings và chat, và một giao diện webhook đơn giản mà bạn có thể kiểm tra từ Postman. Bot sẽ tiếp nhận các tệp của bạn, chia nhỏ và nhúng chúng, lưu trữ các vector, truy xuất các đoạn văn có liên quan nhất và trả lời bằng các trích dẫn — đồng thời nó giữ bộ nhớ phiên trong các lượt.
Tại sao lại là agentic RAG?
RAG cổ điển chỉ truy xuất các đoạn và trả lời. Agentic RAG thêm lập kế hoạch và sử dụng công cụ: chatbot có thể gọi công cụ truy xuất của bạn, tra cứu các hàng có cấu trúc và duy trì ngữ cảnh trong một cuộc trò chuyện. Điều đó làm cho nó đáng tin cậy hơn, dễ giải thích hơn và hữu ích cho công việc thực tế.
Những gì bạn sẽ xây dựng (tóm tắt):
- Màu xanh lam: Tiếp nhận — theo dõi một thư mục, trích xuất văn bản (PDF/CSV/Docs), chia nhỏ → nhúng → upsert vào Postgres (pgvector).
- Màu đỏ: Bootstrap — tạo một bảng documents và một hàm tương đồng match_documents().
- Màu xanh lá cây: Công cụ — một công cụ SQL có thể tái sử dụng, chạy tìm kiếm vector thông qua match_documents(…).
- Màu vàng: Chat agent — một webhook được bảo mật, mô hình chat, Bộ nhớ Chat Postgres và các lệnh gọi công cụ, trả về câu trả lời kèm theo nguồn.
Những gì bạn sẽ học:
- Cách kết nối các node n8n để tiếp nhận RAG, embeddings, upserts vector, truy xuất và bộ nhớ chat.
- Cách thiết lập Postgres 16 + pgvector (và phải làm gì nếu bạn bắt đầu trên PG12).
- Cách bảo mật và kiểm tra webhook của bạn bằng tiêu đề x-api-key từ Postman.
- Cách gỡ lỗi các cạm bẫy phổ biến (IPv4/IPv6, thiếu vector.control, quyền mở rộng, thiếu bảng, khóa bộ nhớ).
Stack & liên kết:
- n8n (tự động hóa & agents): //docs.n8n.io/
- PostgreSQL: //www.postgresql.org/
- pgvector (loại vector & indexes): //github.com/pgvector/pgvector
- OpenAI (embeddings + mô hình chat): //platform.openai.com/docs/
- Postman (kiểm tra webhook): //www.postman.com/
- Supabase (Postgres được quản lý): //supabase.com/
- DigitalOcean Droplets (VM host): //docs.digitalocean.com/products/droplets/
Các tài nguyên chính tôi đã sử dụng và điều chỉnh (ghi công):
- Medium: Mastering Agentic RAG in n8n — Build RAG Chatbot that Plans, Thinks, and Answers
//towardsdev.com/mastering-agentic-rag-in-n8n-build-rag-chatbot-that-plans-thinks-and-answers-f17edfc0411e - YouTube walkthrough: //youtu.be/mQt1hOjBH9o
Lưu ý: các nguồn trên đã được vài tháng — n8n đã thay đổi một số giao diện người dùng và mặc định của node. Tôi sẽ hiển thị các cài đặt chính xác mà tôi đã sử dụng (và các bản sửa lỗi) để bạn có thể làm theo trên các phiên bản hiện tại.
Cách cấu trúc hướng dẫn này.
Chúng ta sẽ đi từng bước qua các khu vực được mã hóa màu: thiết lập cơ sở dữ liệu (đỏ), tiếp nhận (xanh lam), công cụ truy xuất (xanh lục) và luồng chat agent (vàng). Tôi sẽ bao gồm các SQL/biểu thức chính xác, cài đặt node và một hộp khắc phục sự cố cho mỗi bước khó khăn.
Hãy bắt đầu.
Đầu tiên: chuẩn bị cơ sở dữ liệu — cài đặt/xác minh pgvector, tạo bảng documents và hàm match_documents() — sau đó chúng ta sẽ tiếp nhận các tệp mẫu và trò chuyện với chúng bằng các nguồn.
Vùng ĐỎ — Khởi động cơ sở dữ liệu (pgvector, bảng, hàm tìm kiếm)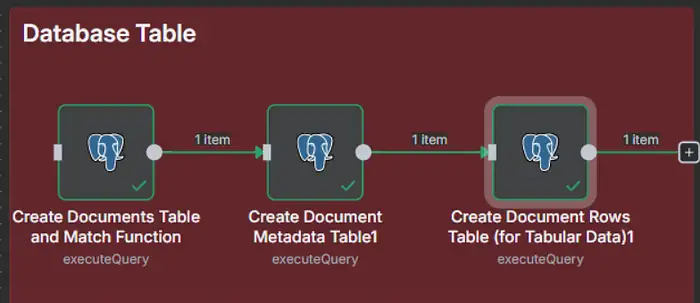
Mục tiêu
Tạo lược đồ mà pipeline của bạn cần:
- document_metadata — một hàng cho mỗi tệp (Drive file_id, tiêu đề, url…)
- documents — các đoạn văn bản + embeddings, được liên kết với tệp thông qua doc_id
- document_rows — các hàng dạng bảng (CSV/XLSX) được liên kết thông qua doc_id
- match_documents() — tìm kiếm tương đồng cosine trên embeddings
Hoạt động trên PostgreSQL 16 + pgvector (cục bộ hoặc Supabase).
Nếu bạn vẫn đang ở trên PG12, hãy nâng cấp hoặc cài đặt pgvector, sau đó tiếp tục.
0) (Chạy một lần) Bật pgvector
Postgres cục bộ (siêu người dùng):
CREATE EXTENSION IF NOT EXISTS vector;
Supabase: chạy tương tự trong trình chỉnh sửa SQL. (Bạn không cần siêu người dùng trong Supabase; chỉ cần bật tiện ích mở rộng.)
Xác minh: \dx sẽ liệt kê vector.
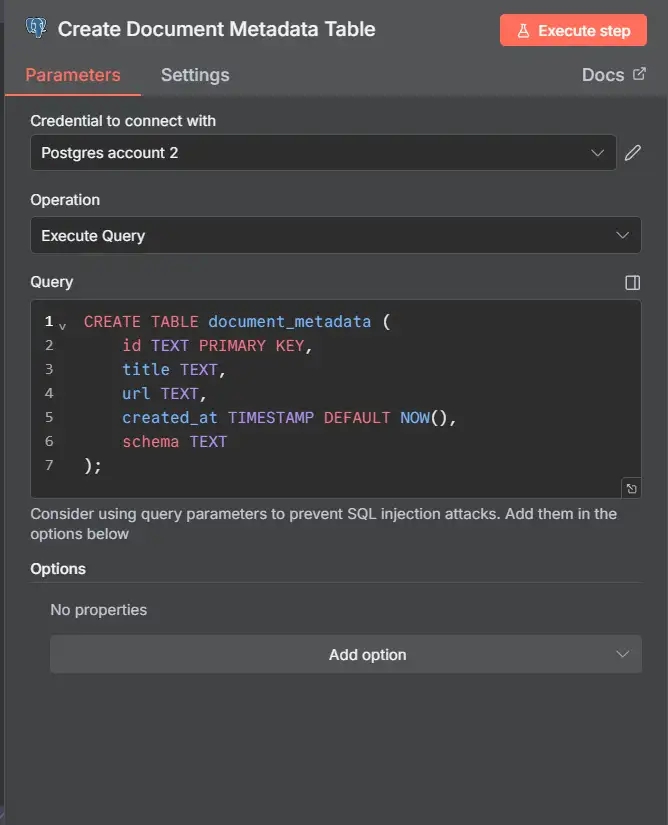
1) Tạo document_metadata (chạy trước)
Tên node: Create Document Metadata Table
Khi nào: một lần, khi thiết lập
CREATE TABLE IF NOT EXISTS document_metadata ( id TEXT PRIMARY KEY, -- Google Drive file_id title TEXT, url TEXT, created_at TIMESTAMPTZ DEFAULT NOW(), schema JSONB ); CREATE INDEX IF NOT EXISTS document_metadata_created_at_idx ON document_metadata (created_at DESC);
Tại sao trước? Bảng tiếp theo (documents) tham chiếu đến bảng này.
2) Tạo documents + indexes + match_documents() (chạy thứ hai)
Tên node: Create Documents Table & Match Function
Khi nào: một lần, khi thiết lập
-- Table to store text chunks + their embeddings CREATE TABLE IF NOT EXISTS documents ( id BIGSERIAL PRIMARY KEY, doc_id TEXT NOT NULL REFERENCES document_metadata(id) ON DELETE CASCADE, content TEXT, metadata JSONB, chunk_index INT, -- optional: order chunks/pages embedding VECTOR(1536) -- OpenAI text-embedding-3-* uses 1536 dims ); -- Helpful indexes CREATE INDEX IF NOT EXISTS documents_doc_id_idx ON documents (doc_id); CREATE INDEX IF NOT EXISTS documents_metadata_gin ON documents USING GIN (metadata); -- ANN index for fast cosine search (after extension is enabled) CREATE INDEX IF NOT EXISTS documents_embedding_ivfflat ON documents USING ivfflat (embedding vector_cosine_ops) WITH (lists = 100); -- Cosine similarity search function CREATE OR REPLACE FUNCTION match_documents( query_embedding VECTOR(1536), match_count INT, filter JSONB DEFAULT '{}'::JSONB ) RETURNS TABLE ( id BIGINT, doc_id TEXT, content TEXT, metadata JSONB, chunk_index INT, similarity DOUBLE PRECISION ) LANGUAGE plpgsql AS $$ BEGIN RETURN QUERY SELECT d.id, d.doc_id, d.content, d.metadata, d.chunk_index, 1 - (d.embedding <=> query_embedding) AS similarity FROM documents d WHERE (filter IS NULL OR filter = '{}'::jsonb OR d.metadata @> filter) ORDER BY d.embedding <=> query_embedding LIMIT match_count; END; $$;
Ghi chú
Chúng tôi trả về doc_id và chunk_index để agent có thể trích dẫn đúng tệp và xây dựng lại/theo dõi các đoạn.
vector(1536) khớp với text-embedding-3-small. Nếu bạn chuyển sang mô hình 3072 chiều sau này, hãy thay đổi cột và lập chỉ mục lại.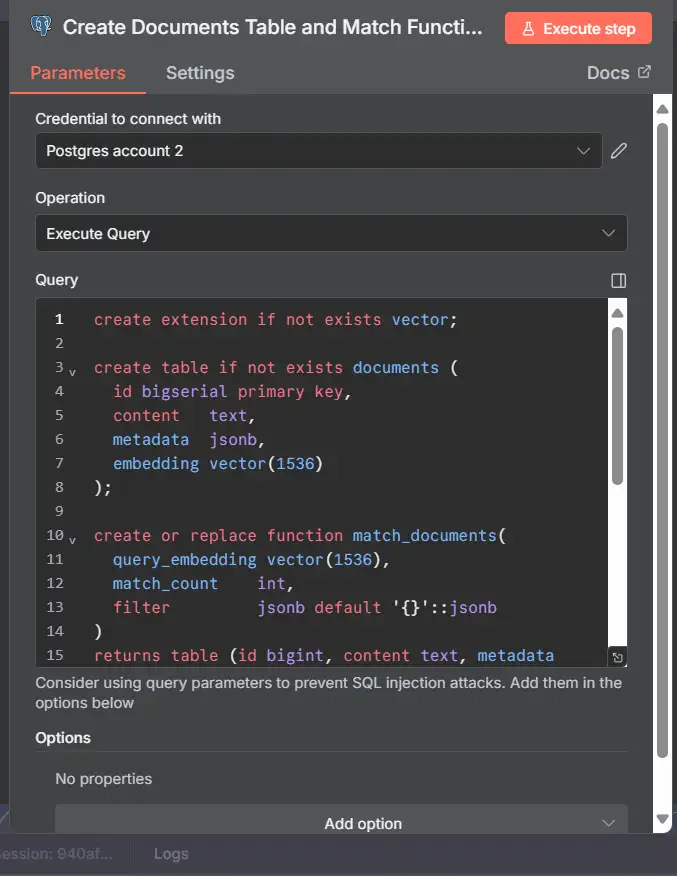
3) Tạo document_rows (chạy thứ ba)
Tên node: Create Document Rows Table (for Tabular Data)
Khi nào: một lần, khi thiết lập
CREATE TABLE IF NOT EXISTS document_rows ( id BIGSERIAL PRIMARY KEY, doc_id TEXT NOT NULL REFERENCES document_metadata(id) ON DELETE CASCADE, row_index INT, -- original row number if available row_data JSONB, -- full row as JSON (column -> value) text_content TEXT, -- flattened text for QA over tables row_hash TEXT UNIQUE -- optional: dedupe guard ); CREATE INDEX IF NOT EXISTS document_rows_doc_id_idx ON document_rows (doc_id); CREATE INDEX IF NOT EXISTS document_rows_row_gin ON document_rows USING GIN (row_data);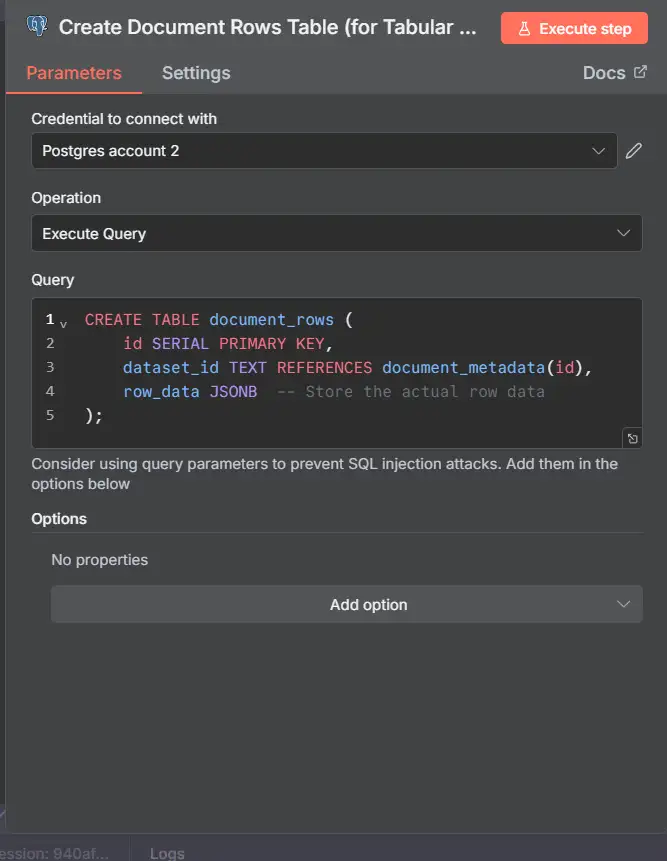
4) Grants (tùy chọn, cho vai trò ứng dụng không phải siêu người dùng)
Nếu người dùng DB n8n của bạn là n8n, hãy cấp các quyền cơ bản:
GRANT USAGE ON SCHEMA public TO n8n; GRANT SELECT, INSERT, UPDATE, DELETE ON ALL TABLES IN SCHEMA public TO n8n; ALTER DEFAULT PRIVILEGES IN SCHEMA public GRANT SELECT, INSERT, UPDATE, DELETE ON TABLES TO n8n;
5) Kiểm tra nhanh tính hợp lệ
Chạy các lệnh này trong cùng cơ sở dữ liệu mà quy trình làm việc của bạn sử dụng:
-- pgvector installed? SELECT extname FROM pg_extension WHERE extname='vector'; -- tables exist? SELECT tablename FROM pg_tables WHERE schemaname='public' AND tablename IN ('document_metadata','documents','document_rows'); -- function exists? SELECT proname FROM pg_proc WHERE proname='match_documents';
Nếu bạn đã tiếp nhận ít nhất một tệp:
-- chunks linked to files SELECT doc_id, COUNT(*) AS chunks FROM documents GROUP BY 1 ORDER BY chunks DESC LIMIT 5; -- any null links? (should be 0) SELECT COUNT(*) FROM documents WHERE doc_id IS NULL;
Bây giờ bạn có:
- Một danh mục các tệp (document_metadata)
- Một kho lưu trữ đoạn văn bản được vector hóa (documents) có liên kết doc_id
- Một kho lưu trữ dạng bảng cho CSV/XLSX (document_rows)
- Một hàm tìm kiếm (match_documents) được sử dụng bởi các công cụ Green của bạn
Tiếp theo, quá trình tiếp nhận Blue của bạn sẽ upsert metadata, xóa các hàng cũ theo doc_id, trích xuất + chia nhỏ, nhúng và chèn vào documents (và document_rows cho các bảng)
Vùng Xanh lam (Tiếp nhận): Google Drive → Postgres (pgvector) cho RAG
Pipeline “màu xanh lam” này làm gì
Mục tiêu: Khi một tệp trong Google Drive được tạo hoặc cập nhật, chúng ta:
- thu thập metadata của nó (file_id, tiêu đề, url, mimeType)
- dọn dẹp mọi hàng/đoạn cũ cho tài liệu đó
- tải xuống/chuyển đổi tệp
- trích xuất văn bản (PDF/Text) hoặc hàng (CSV/Excel/Sheets)
- (tùy chọn) ghi các hàng dạng bảng vào bảng document_rows
- chia văn bản dài thành các đoạn
- nhúng mỗi đoạn bằng OpenAI
- lưu trữ các đoạn + embeddings trong bảng documents cho RAG.
1) Danh sách kiểm tra thông tin đăng nhập
- Google Drive OAuth2 (cho Trigger + Download File)
- OpenAI (cho Embeddings + Summarize tùy chọn)
- Postgres (DB cục bộ trên máy chủ của bạn) — đã cài đặt pgvector
- Supabase (URL + khóa service_role; pgvector được bật với create extension vector;)
2) Google Drive: “File Created” + “File Updated”
2.1 Tạo thông tin đăng nhập Google OAuth (một lần)
- Đi tới Google Cloud Console → tạo dự án.
- APIs & Services → Enabled APIs & services → Enable APIs → Google Drive API.
- Credentials → Create Credentials → OAuth client ID → Web application.
- Thêm URI chuyển hướng được ủy quyền:
//<your-n8n-host>/rest/oauth2-credential/callback - Đừng quên thêm địa chỉ gmail của bạn vào người dùng thử nghiệm từ Google Auth Platform → phần Đối tượng (Nó phải là bên ngoài)
- Sao chép Client ID và Client Secret.
2.2 Thêm thông tin đăng nhập Google trong n8n
- Credentials → Google Drive OAuth2 API
- Dán Client ID / Client Secret
- Kết nối tài khoản (màn hình chấp thuận của Google).
2.3 Node: Google Drive Trigger (2 nodes)
Bạn sẽ thêm hai node trigger để có thể phản ứng với cả hai sự kiện:
- File Created
- Resource: File
- Operation: Watch
- Drive: My Drive (hoặc một thư mục cụ thể thông qua Folder ID)
- Events: Created
- File Types (tùy chọn): nếu bạn muốn giới hạn (PDF, CSV, XLSX, Google Docs/Sheets…)
- Start Watching: ON (lần đầu tiên để đăng ký kênh theo dõi)
- Credentials: Google Drive OAuth của bạn
- File Updated
- Tương tự như trên, nhưng Events: Updated
💡 Lọc thư mục: lấy ID của thư mục từ URL Drive và đặt Folder thành ID đó để bạn không tiếp nhận toàn bộ ổ đĩa của mình.
Những gì bạn nhận được từ các node này (JSON):
{ "id": "1V-HrbpFgWKDonx8f-5dY_n7Ym3TxAw6", "name": "sample.csv", "mimeType": "text/csv", "webViewLink": "//drive.google.com/file/d/...", "modifiedTime": "2025-08-21T11:20:01Z", ... }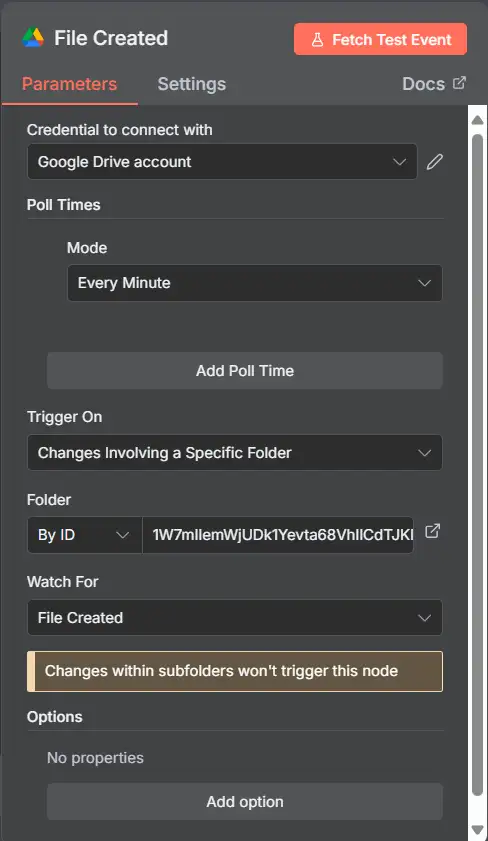
3) Loop Over Items (tùy chọn nhưng tiện dụng)
Nếu bạn hợp nhất cả hai trigger vào cùng một đường dẫn, hãy thả một node Loop Over Items để chuẩn hóa thành một luồng duy nhất.
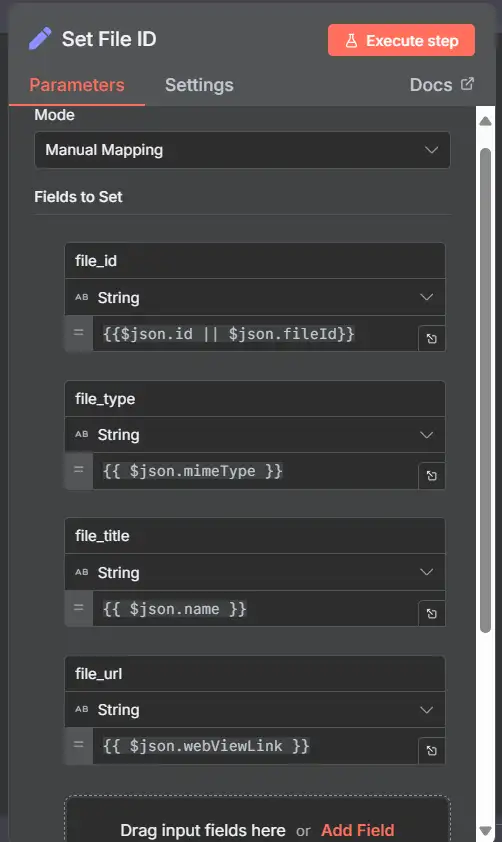
4) Set File ID (Set node)
Tạo một JSON nhỏ mà bạn sẽ sử dụng ở mọi nơi:
Fields to Set (dưới dạng biểu thức):
- file_id →
{{$json.id}} - file_title →
{{$json.name}} - file_type →
{{$json.mimeType}} - file_url →
{{$json.webViewLink}}
5) Xóa dữ liệu cũ (để việc tiếp nhận lại là idempotent)
Chúng tôi xóa các hàng bảng trước đó và các đoạn vector cho cùng một file_id trước khi chèn dữ liệu mới.
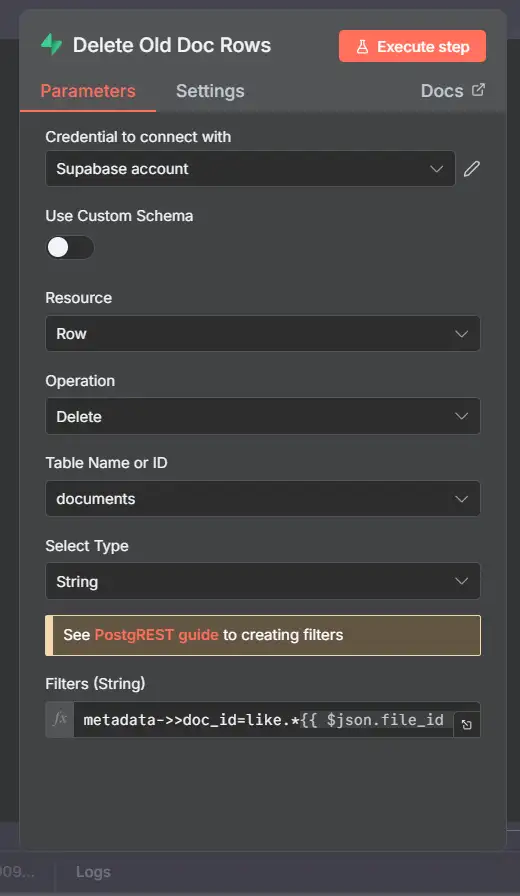
5.1 Xóa khỏi document_rows (dạng bảng)
- Supabase
- Node: Supabase → Row → Delete
- Table: document_rows
- Select Type: Build Manually
- Condition: doc_id Equals
{{ $('Set File ID').item.json.file_id }}
- Local Postgres (SQL)
- Node: Postgres → Execute Query
delete from document_rows where doc_id = $1;- Query Parameters:
{{ $('Set File ID').item.json.file_id }}
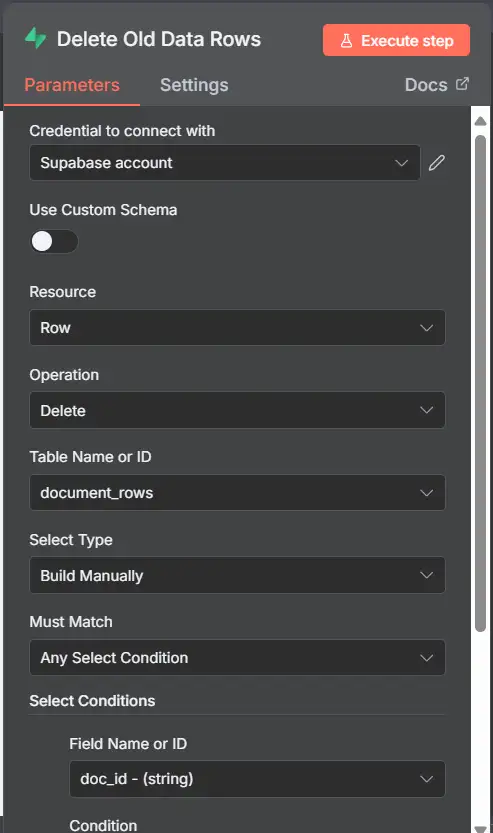
5.2 Xóa các đoạn khỏi documents (bảng vector)
Ưu tiên một cột doc_id thực trong documents. Nếu bạn chỉ lưu trữ doc_id trong JSON metadata, hãy sử dụng metadata->>’doc_id’.
- Supabase
- Node: Supabase → Row → Delete
- Table: documents
- Condition: either
- doc_id Equals
{{ $('Set File ID').item.json.file_id }} - OR metadata->>doc_id Equals
{{ $('Set File ID').item.json.file_id }}
- doc_id Equals
- Local Postgres (SQL)
-- if you added a real column: delete from documents where doc_id = $1; -- if kept in metadata only: delete from documents where metadata->>'doc_id' = $1;- Param: file_id
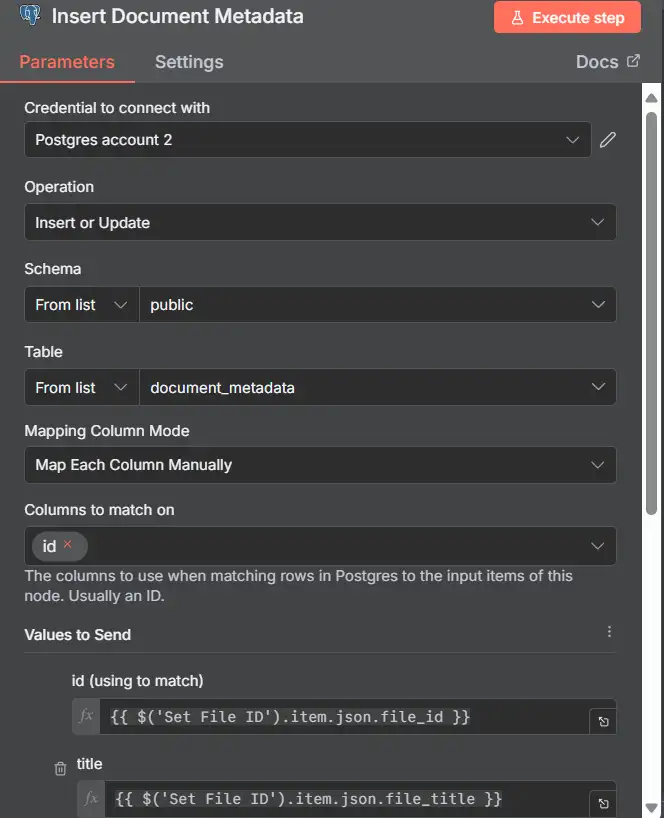
6) Upsert document metadata
Lưu/cập nhật thông tin cơ bản cho tệp này.
- Supabase
- Node: Supabase → Row → Upsert
- Table: document_metadata
- Conflict Column: id
- Body:
{ "id": "{{ $('Set File ID').item.json.file_id }}", "title": "{{ $('Set File ID').item.json.file_title }}", "url": "{{ $('Set File ID').item.json.file_url }}", "schema": {}
- Local Postgres (SQL)
insert into document_metadata (id, title, url, schema) values ($1, $2, $3, '{}'::jsonb) on conflict (id) do update set title = excluded.title, url = excluded.url;- Params: file_id, file_title, file_url
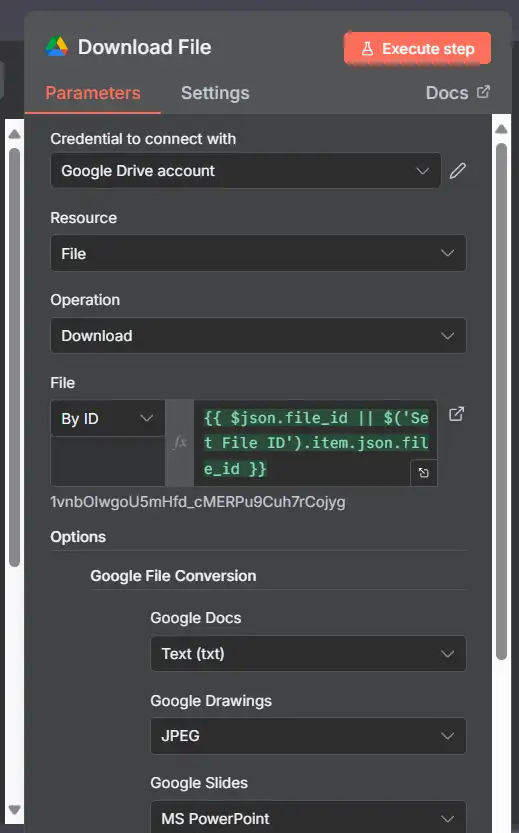
7) Download File (Google Drive → Download)
- Node: Google Drive
- Operation: Download File
- File ID:
{{ $('Set File ID').item.json.file_id }} - Nếu tệp là Google Doc/Sheet gốc: đặt Export MIME Type:
- Google Docs → text/plain (hoặc application/pdf)
- Google Sheets → text/csv (hoặc application/vnd.openxmlformats-officedocument.spreadsheetml.sheet)
- Đầu ra bao gồm dữ liệu nhị phân với fileName, mimeType, size.
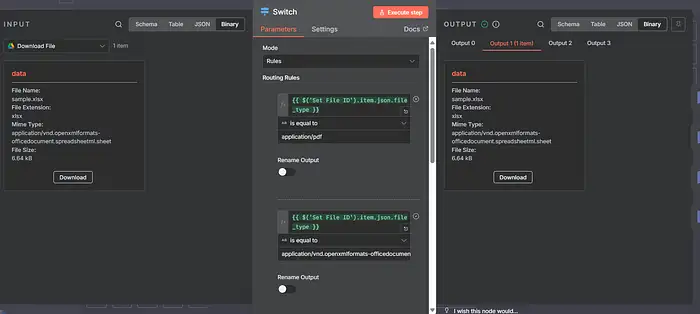
8) Switch (route by file_type)
Tạo Quy tắc dựa trên loại mime (bạn cũng có thể sử dụng mimeType nhị phân, cái nào cũng được):
- application/pdf → Extract PDF Text
- text/plain → Extract Document Text
- text/csv → Extract from CSV
- application/vnd.ms-excel / application/vnd.openxmlformats-officedocument.spreadsheetml.sheet → Extract from Excel
- application/vnd.google-apps.document → (exported as text/plain) → Extract Document Text
- application/vnd.google-apps.spreadsheet → (exported as csv/xlsx) → Extract from CSV/Excel
9) Extraction nodes
9.1 PDFs
- Node: Extract PDF Text
- Binary Property: data
- Output:
{ text: "...", page: 1 }… merged or per page (depending on node).
9.2 Plain text (and Google Docs exported as text)
- Node: Extract Document Text
- Binary Property: data
- Output:
{ text: "full plain text" }
9.3 CSV
- Node: Extract from CSV
- Binary Property: data
- Options: delimiter (often ,), header row yes
- Output: one item per row (JSON columns)
9.4 Excel / Google Sheets (exported to XLSX)
- Node: Extract from Excel (XLSX)
- Binary Property: data
- Options: sheet name/index, header row yes
- Output: one item per row
10) Insert tabular rows (optional) → document_rows
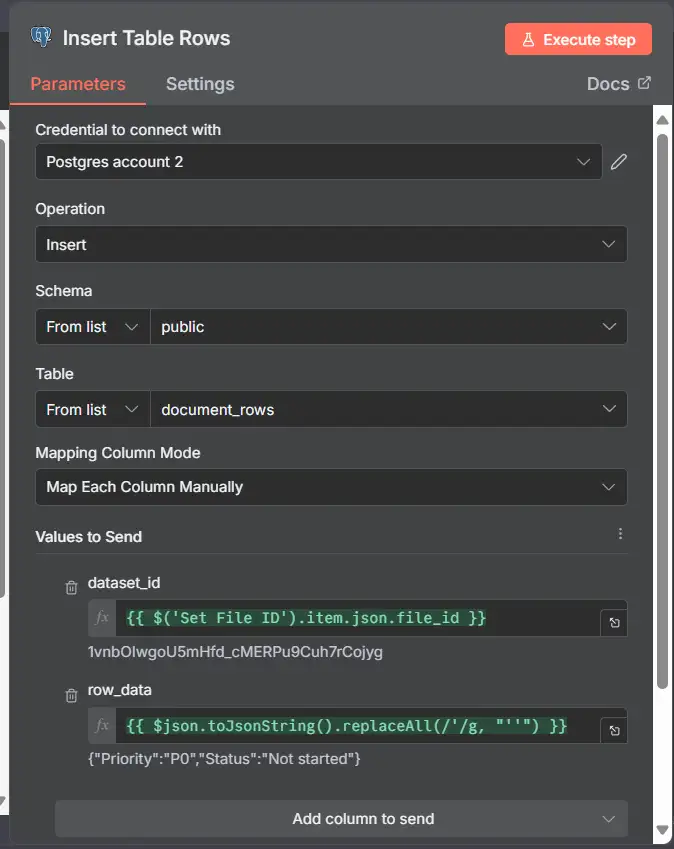
Nếu tệp là CSV/Excel/Sheets, bạn có thể muốn lưu trữ các hàng đó trong một bảng.
- Supabase
- Node: Supabase → Row → Insert (Many) or Insert
- Table: document_rows
- Body for each row:
{ "doc_id": "{{ $('Set File ID').item.json.file_id }}", "row_index": "{{ $json.rowNumber || $json._row || $itemIndex }}", "row_data": {{ JSON.stringify($json) }}, "text_content": "{{ Object.values($json).join(' ') }}" }
- Local Postgres (SQL)
- Node: Postgres → Execute Query (Many)
- Query:
insert into document_rows (doc_id, row_index, row_data, text_content) values ($1, $2, $3::jsonb, $4); - Parameter mapping per item:
- $1 =
{{ $('Set File ID').item.json.file_id }} - $2 =
{{ $json.rowNumber || $json._row || $itemIndex }} - $3 =
{{ JSON.stringify($json) }} - $4 =
{{ Object.values($json).join(' ') }}
- $1 =
11) Summarize (optional)
- Node: OpenAI Chat Model
- Prompt: “Summarize the document in 3–5 bullet points…”
- Bạn có thể lưu trữ bản tóm tắt trở lại document_metadata.schema.summary sau này.
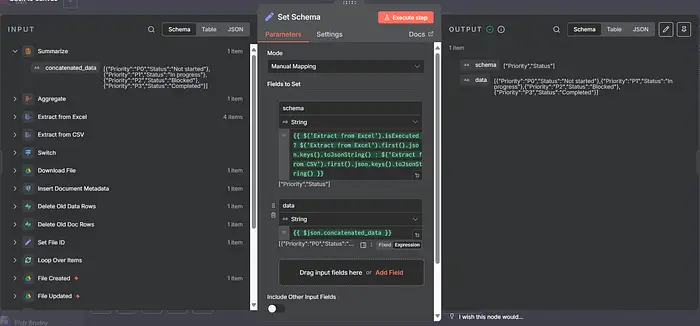
12) Set Schema (Set node)
Xây dựng một đối tượng nhỏ gọn với thông tin bạn quan tâm (cho giao diện người dùng chat / lọc):
{ "doc_id": "{{ $('Set File ID').item.json.file_id }}", "title": "{{ $('Set File ID').item.json.file_title }}", "url": "{{ $('Set File ID').item.json.file_url }}", "detected_type": "{{ $('Set File ID').item.json.file_type }}", "has_tabular": {{ $items().some(i => i.json.isTableRow) ? true : false }} }
Thay thế isTableRow bằng cách bạn gắn thẻ các hàng; hoặc chỉ để doc_id/title/url.
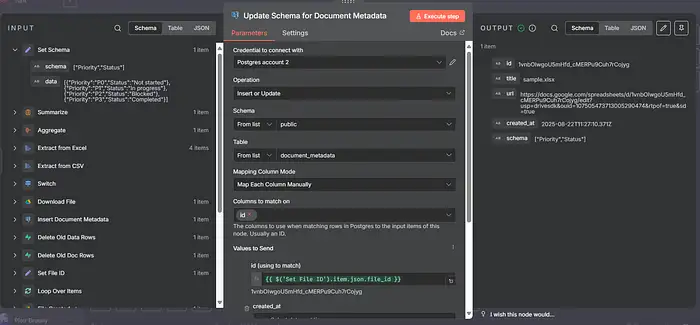
13) Update schema in document_metadata
- Supabase
- Node: Supabase → Row → Update
- Table: document_metadata
- Condition: id Equals
{{ $('Set File ID').item.json.file_id }} - Body:
{ "schema": {{ JSON.stringify($json) }} }
- Local Postgres (SQL)
update document_metadata set schema = $2::jsonb where id = $1;- Params: file_id,
{{ JSON.stringify($json) }}
14) Character Text Splitter (chunking)
- Node: Character Text Splitter
- Text Field: choose from previous extractor (text)
- Chunk Size: 800 (example)
- Chunk Overlap: 100
- Output: one item per chunk
{ text: "..." } - Sau đó thêm một node Set để gắn doc_id vào mỗi đoạn:doc_id →
{{ $('Set File ID').item.json.file_id }}
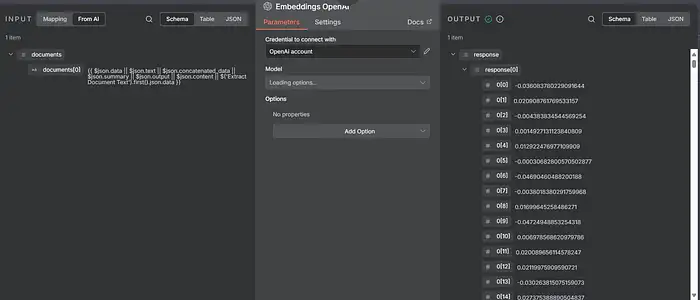
15) OpenAI Embeddings
- Node: Embeddings: OpenAI
- Model: text-embedding-3-small (1536 dims)
- Input: the chunk text
- Output: adds embedding:
[ ... 1536 floats ... ]per item.
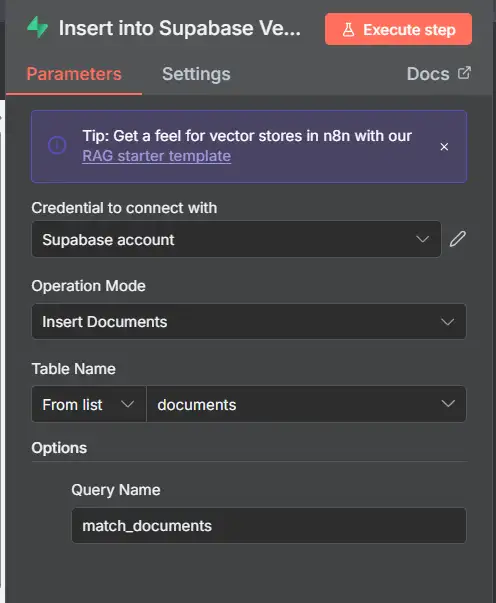
16) Insert chunks + embeddings into documents
Chúng tôi lưu trữ (content, metadata, doc_id, embedding) cho mỗi đoạn.
Nếu bạn đã thêm một cột doc_id thực (được khuyến nghị)
- Supabase
- Node: Supabase → Row → Insert (Many)
- Table: documents
- Body per chunk:
{ "content": "{{ $json.text }}", "metadata": {{ JSON.stringify({ doc_id: $('Set File ID').item.json.file_id, title: $('Set File ID').item.json.file_title, url: $('Set File ID').item.json.file_url }) }}, "doc_id": "{{ $('Set File ID').item.json.file_id }}", "embedding": {{ $json.embedding }} }
- Local Postgres (SQL)
- Node: Postgres → Execute Query (Many)
insert into documents (content, metadata, doc_id, embedding) values ($1, $2::jsonb, $3, $4);- Params per item:
- $1 =
{{ $json.text }} - $2 =
{{ JSON.stringify({ doc_id: $('Set File ID').item.json.file_id, title: $('Set File ID').item.json.file_title, url: $('Set File ID').item.json.file_url }) }} - $3 =
{{ $('Set File ID').item.json.file_id }} - $4 =
{{ $json.embedding }}
- $1 =
Lưu ý: với pgvector 0.5+ và PostgREST, Supabase chấp nhận các mảng JSON cho vector(1536) trực tiếp; Postgres SQL Insert cũng chấp nhận các mảng JSON nếu trình điều khiển ánh xạ nó (node n8n Postgres thực hiện).
17) (Tùy chọn) Default Data Loader / “doc → chunks” join
Nếu bạn sử dụng một node “Data Loader” (như trong canvas của tôi) cho agent, hãy cung cấp nó từ các đoạn bạn vừa chèn hoặc từ cùng một JSON được tạo trước khi chèn. Công việc của nó là cung cấp cho agent một “tài liệu với các đoạn + metadata” được chuẩn hóa.
Ghi chú & các lỗi thường gặp
- Sử dụng khóa service_role cho việc tiếp nhận Supabase (khóa anon sẽ không cho phép xóa). Chỉ giữ nó ở phía máy chủ.
- Nếu Supabase delete không thể lọc metadata->>doc_id trong giao diện người dùng node, hãy thêm một cột doc_id thực và lọc trên nó (dù sao thì cũng sạch hơn và nhanh hơn).
- Đối với Google Docs/Sheets, bạn phải xuất khi tải xuống (Drive lưu trữ chúng dưới dạng các loại gốc của Google).
- Nếu việc chạy lại không thay đổi kết quả, hãy kiểm tra xem các bước Delete (5.1, 5.2) có thực sự khớp với cùng một file_id hay không.
- Nếu embeddings không thành công, hãy xác nhận khóa OpenAI của bạn và tên mô hình (1536 dims) và bạn đang truyền các mảng float thuần túy.
Vùng Vàng: “RAG AI Agent với Giao diện Chat”
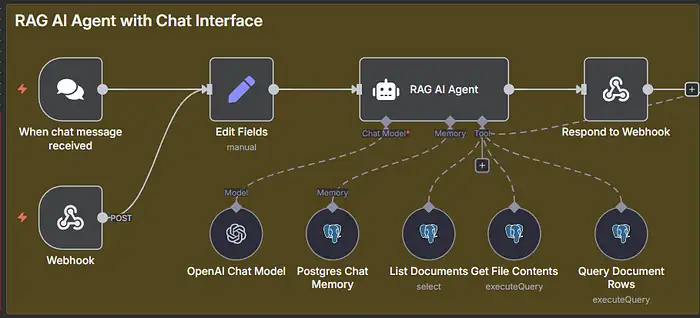
Khối này làm gì
Nó hiển thị bot của bạn dưới dạng một điểm cuối HTTP an toàn, chuẩn hóa đầu vào, tải/cập nhật bộ nhớ chat, cho phép agent suy nghĩ và gọi các công cụ của bạn (tìm kiếm vector + tra cứu SQL), sau đó trả về một phản hồi JSON sạch.
Đường dẫn dữ liệu cấp cao:
Webhook → Edit Fields → (Memory + Model + Tools) → RAG Agent → Respond to Webhook
Các đường chấm vào agent là “khả năng”, không phải luồng dữ liệu:
- Model: Mô hình OpenAI Chat
- Memory: Bộ nhớ Chat Postgres
- Tools: 1) Tìm kiếm kho lưu trữ vector, 2) Lấy văn bản đầy đủ của tài liệu, 3) Truy vấn các hàng dạng bảng
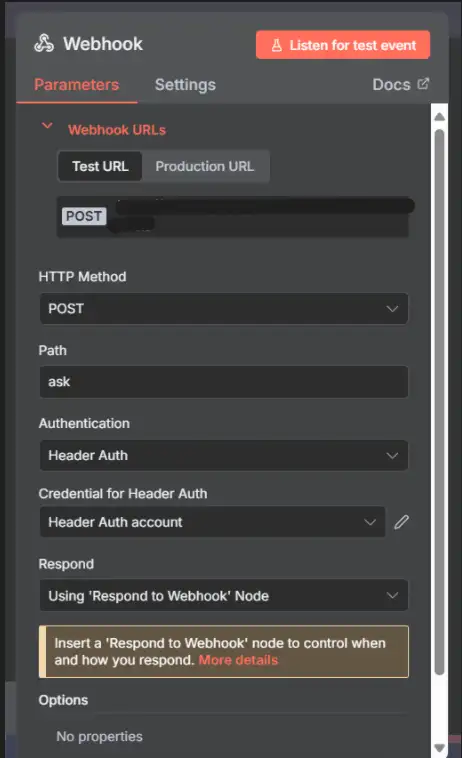
1) Webhook — nhận chat một cách an toàn
- Mục đích: điểm cuối POST bên ngoài mà UI/Postman của bạn gọi.
- HTTP Method: POST
- Path: ask
- Your URLs:
- Test:
//<your-n8n-host>/webhook-test/ask - Prod (when workflow is Active):
//<your-n8n-host>/webhook/ask
- Test:
- Response: Respond later (we’ll answer with Respond to Webhook at the end)
- Auth: use a Header Auth credential so only clients with your secret can call it
- Credentials → Header Auth
- Name: x-api-key
- Value:
<a long random secret>
Bạn phải gửi tiêu đề x-api-key: <that secret> hoặc bạn sẽ nhận được 403 Forbidden.
JSON body dự kiến (giữ cho nó đơn giản và nhất quán):
{ "message": "What is in sample.csv? List the items and amounts.", "session_id": "postman-001", "user_id": "postman" }
Các lỗi thường gặp
- 403 Forbidden → missing/wrong x-api-key.
- Nếu bạn định thay đổi tên trường, bạn sẽ cập nhật ánh xạ trong node tiếp theo.
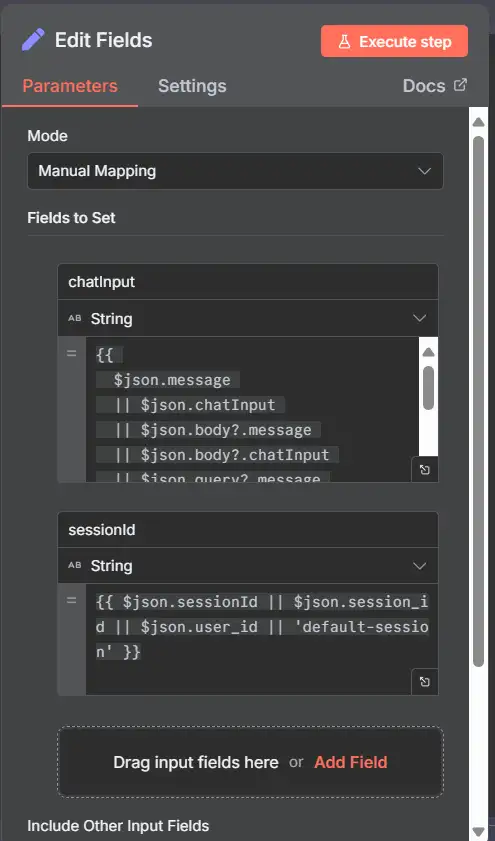
2) Edit Fields — chuẩn hóa payload
- Mục đích: đảm bảo rằng các node hạ lưu luôn thấy chatInput và sessionId.
- Mode: Manual Mapping
- Fields to set
- chatInput (String)
{{$json.message || $json.chatInput || $json.body?.message}} - sessionId (String)
{{$json.session_id || $json.user_id || 'default-session'}}
- chatInput (String)
- Bao gồm các trường nhập liệu khác: Off (cleanest)
- Chạy một lần với đầu vào mẫu và xác nhận đầu ra vừa có:
{ "chatInput": "...", "sessionId": "..." }
3) Postgres Chat Memory — lưu giữ các lượt trò chuyện
- Mục đích: agent thấy các lượt trước đó cho cùng một sessionId.
- Credential: Postgres/Supabase đang hoạt động của bạn (cùng họ DB được sử dụng trong Red/Blue)
- Session ID: Define below
- Key: chatInput ← must set this(This fixes the classic error “input values have 3 keys, you must specify an input key or pass only 1 key as input.”)
- Session ID (Expression):
{{$json.sessionId}}- Tên bảng:
n8n_chat_histories(hoặc tên bạn chọn)
Mẹo: Bạn có thể xác nhận tin nhắn đang được lưu trữ:
SELECT session_id, COUNT(*) FROM n8n_chat_histories GROUP BY 1 ORDER BY 2 DESC;
4) Mô hình trò chuyện OpenAI — gắn kết não bộ
Mục đích : xác định LLM mà tác nhân sẽ sử dụng.
Mẫu: ví dụ, gpt-4o-minihoặc mẫu bạn thích
Số lượng Token tối đa/Nhiệt độ: phù hợp với phong cách của bạn (thường là 0,2–0,7)
Đính kèm vào tác nhân bằng liên kết “Model” có dấu chấm (không có dây dữ liệu trực tiếp).
5) Công cụ (đính kèm liên kết “Công cụ” có dấu chấm)
Những điều này cho phép tác nhân thực hiện mọi việc thay vì đoán — chính xác những gì bạn đã xây dựng trong Red/Blue.
5.1 Supabase Vector Store (Tìm kiếm)
Bạn đã kết nối điều này trong khối Green. Tác nhân truyền một chuỗi truy vấn, nó trả về các khối top-k với doc_id, content, và độ tương tự.
Đảm bảo mô tả công cụ cho tác nhân biết khi nào nên sử dụng công cụ (ví dụ: “sử dụng công cụ này để tìm các phần có liên quan cho các câu hỏi không có cấu trúc”).
5.2 “Liệt kê tài liệu, lấy nội dung tệp” (SQL → toàn văn cho một tệp)
Mục đích : cho doc_id(ID tệp Google Drive của bạn), trả về toàn bộ văn bản (tất cả các đoạn được nối lại).
Loại nút: Postgres → Thực thi truy vấn
Hoạt động: Execute Query
Truy vấn:
SELECT string_agg(content, ‘ ‘) AS document_text FROM documents WHERE doc_id = $1 GROUP BY doc_id;
Tham số truy vấn: ánh xạ đối số công cụ của tác nhân (id tệp)
Nếu bạn đặt tên cho đối số công cụ file_idtrong mô tả công cụ:
{{$fromAI(‘file_id’)}}
(hoặc {{$json.file_id}}nếu bạn tự truyền id cho mình)
Mô tả công cụ (trong tab Công cụ của nút):
“Với một file_id (ID Google Drive), hãy trả về
Toàn bộ văn bản của tài liệu đó thành một chuỗi. Sử dụng tùy chọn này khi bạn cần toàn bộ tệp để suy luận hoặc trích dẫn các đoạn văn dài.
Hình dạng đầu ra (ví dụ): { “document_text”: “All text merged…” }
{ “document_text” : “Tất cả văn bản đã được hợp nhất…” }
5.3 “Truy vấn hàng tài liệu” (SQL → hàng cho CSV/XLSX)
Mục đích : lấy các hàng có cấu trúc từ cùng một tệp (được nối bởi doc_id).
Loại nút: Postgres → Thực thi truy vấn
Hoạt động: Execute Query
Truy vấn (cơ bản):
SELECT * FROM document_rows WHERE doc_id = $1 ORDER BY row_number LIMIT COALESCE($2::int, 50);
Tham số truy vấn:
{{$fromAI(‘file_id’)}}
{{$fromAI(‘limit’) || 50}}
Mô tả công cụ:
“Cho một file_id (ID Google Drive), trả về các hàng dạng bảng từ tệp. Giới hạn tùy chọn (mặc định là 50). Sử dụng tùy chọn này khi người dùng yêu cầu bảng, nội dung CSV, danh sách mục hoặc tổng số.”
⚠️ Tất cả những điều này phụ thuộc vào việc liên kết doc_id của bạn có chính xác hay không (chúng tôi đã sửa lỗi này trước đó):
Trên Blue ingest, hãy thiết lập doc_id = file_idkhi chèn các khối/hàng.
Khi xóa, hãy lọc theo để doc_idkhi nhập lại không bị trùng lặp.
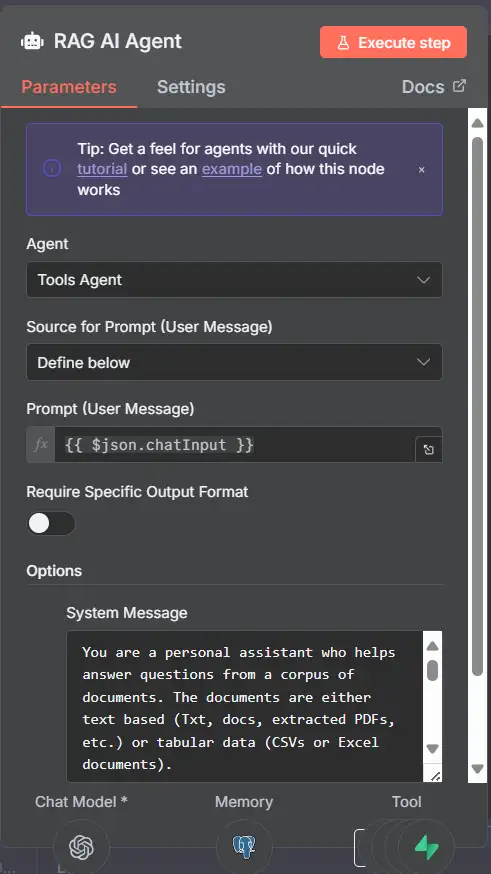
6) RAG AI Agent — người điều phối
Mục đích : đọc hướng dẫn, sử dụng trí nhớ, quyết định khi nào cần gọi công cụ và đưa ra câu trả lời cuối cùng.
Đầu vào : chatInput/ sessionId(từ Chỉnh sửa trường → Bộ nhớ → Tác nhân)
Gắn :
Mô hình : Mô hình trò chuyện OpenAI (có chấm)
Bộ nhớ : Bộ nhớ trò chuyện Postgres (có chấm)
Công cụ :
Supabase Vector Store (tìm kiếm)
Liệt kê tài liệu, lấy nội dung tệp (SQL)
Truy vấn hàng tài liệu (SQL)
Lời nhắc hệ thống (phác thảo):
Bạn là ai và bạn có dữ liệu gì
Khi nào sử dụng tìm kiếm vectơ so với SQL cho các hàng
Trích dẫn đúng tệp (bạn có thể dạy nó hiển thị doc_idhoặc tiêu đề tệp từ siêu dữ liệu)
Nếu bạn sử dụng lược đồ “JSON cuối cùng”, hãy giải thích các khóa chính xác mà bạn mong đợi ( answer, citations, sources, v.v.)
Tại sao người đại diện hiện nay “giữ được sự tỉnh táo”
Bộ nhớ lưu giữ bối cảnh bằng cách sessionId
doc_id tham gia giữ văn bản ↔ siêu dữ liệu ↔ các hàng được liên kết với cùng một tệp
Tác nhân gọi đúng công cụ dựa trên câu hỏi:
“Có gì trong sample.csv?” → công cụ hàng
“Tóm tắt PDF” → lấy nội dung tệp (toàn văn)
“Q chung” → tìm kiếm vectơ
7) Trả lời Webhook — gửi phản hồi
Mục đích : hoàn thành yêu cầu bằng JSON sạch.
Trả lời: Sử dụng Webhook (nút đầu tiên)
Trạng thái HTTP: 200
Phản ứng: JSON
Thân bài (Expression) — hai mẫu chung:
Nếu tác nhân của bạn đưa ra đối tượng JSON cuối cùng (được khuyến nghị):
{{
$json.final_json_response ||
{
“answer”: $json.answer || $json.output || “I answered, but no final JSON was returned.”,
“citations”: $json.citations || []
}
}}
Nếu tác nhân của bạn trả về văn bản thuần túy:
{
“answer”: {{$json.answer || $json.output || $json.text || “No answer returned.”}}
}
Postman test (sao chép-dán)
Lời yêu cầu
POST //<your-n8n-host>/webhook-test/ask
Content-Type: application/json
x-api-key: <your-secret>
Body
{
“message”: “What is in sample.csv? List the items and amounts.”,
“session_id”: “postman-001”,
“user_id”: “postman”
}
Expect
{
“answer” : “…” ,
“citations” : [ { “doc_id” : “1abc…” , “similarity” : 0.88 } ]
}
Khắc phục sự cố (nhanh)
403 Forbidden → sai/thiếux-api-key
“input values have 3 keys giá trị đầu vào có 3 khóa…” → trong Postgres Chat Memory , đặt Key = chatInput
“permission denied to create extension ‘vector’ quyền tạo phần mở rộng ‘vector’ bị từ chối” → chạy CREATE EXTENSION vector;với tư cách siêu người dùng (chúng tôi đã thực hiện việc này khi nâng cấp lên PG16)
Agent cites wrong file / can’t fetch rows Tác nhân trích dẫn tệp sai / không thể lấy hàng → xác minh doc_id :
Khi nhập, thiết lập doc_id = file_idcho từng khối/hàng
Khi xóa, lọc theo doc_id
Công cụ SQL của bạn lọc theo doc_id = $1
SQL lành mạnh:
SELECT doc_id, COUNT(*) FROM documents GROUP BY 1 ORDER BY 2 DESC;
SELECT doc_id, COUNT(*) FROM document_rows GROUP BY 1 ORDER BY 2 DESC;
Green Zone: Công cụ tác nhân cho RAG (Tìm kiếm vectơ)
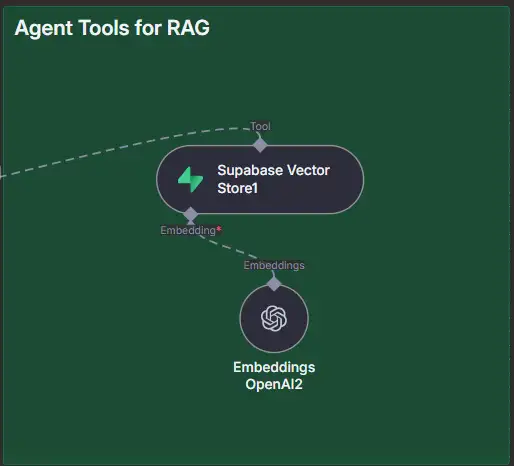
Khối này làm gì
Chuyển đổi câu hỏi của người dùng thành nội dung nhúng .
Chạy tìm kiếm điểm tương đồng trên documentsbảng của bạn (pgvector).
Trả về các khối top-k (cùng với doc_id, content, metadata, similarity) cho tác nhân để tác nhân có thể đưa ra câu trả lời và trích dẫn đúng tệp.
Điều này sử dụng hàm SQL mà bạn đã tạo trong phần Red
create or replace function match_documents(
query_embedding vector(1536),
match_count int,
filter jsonb default ‘{}’::jsonb
)
returns table (id bigint, content text, metadata jsonb, similarity double precision) …
Và đường ống Blue của bạn đã chèn các khối vào documents( content, metadata, embedding, doc_id, chunk_index ).
1) Nhúng OpenAI2 (được chấm vào kho lưu trữ vector)
Mục đích : chuyển văn bản thành vectơ 1536 chiều (để khớp vector(1536)với DB của bạn).
Thông tin xác thực : khóa API OpenAI của bạn.
Mô hình : text-embedding-3-small (1536 dims)
Nếu bạn chuyển sang text-embedding-3-large(3072 dims), bạn phải thay đổi cột DB và lập chỉ mục lại.
Bạn không cần kết nối nút này với luồng dữ liệu; bạn chỉ cần kết nối nó với kho lưu trữ vector bằng đầu nối chấm Embeddings . Nút kho lưu trữ vector sẽ tự động yêu cầu nhúng khi tìm kiếm hoặc chèn.
Gotchas
Kích thước không khớp = lỗi tức thời. Giữ mô hình và vector(N)đồng bộ.
Tìm kiếm chậm/tốn kém? Bạn có thể thêm chỉ mục IVFFLAT:
CREATE INDEX IF NOT EXISTS documents_embedding_idx ON documents USING ivfflat (embedding vector_cosine_ops) WITH (lists = 100); ANALYZE documents;
2) Supabase Vector Store1 (công cụ tìm kiếm)
Mục đích : hiển thị tìm kiếm pgvector của bạn như một Công cụ mà tác nhân có thể gọi.
2.1 Kết nối
Thông tin xác thực : kết nối Postgres/Supabase đang hoạt động của bạn (giống kết nối bạn đã sử dụng ở nơi khác).
Nếu Supabase có RLS, hãy sử dụng khóa vai trò dịch vụ qua PostgREST — hoặc kết nối trực tiếp qua Postgres như bạn đã làm. Đảm bảo người dùng có thể SELECTsử dụng documentshàm EXECUTE.
2.2 Thao tác: Tìm kiếm / So khớp tài liệu
Hầu hết các nút lưu trữ vector đều cung cấp cho bạn thao tác “Tìm kiếm/Truy vấn” gọi match_documents. Cấu hình:
Truy vấn văn bản (Biểu thức mà công cụ sẽ nhận được từ tác nhân):
{{$fromAI(‘query’) || $json.query || $json.chatInput}}
Top K (match_count) :
{{$fromAI(‘top_k’) || 6}}
Bộ lọc (JSON) — tùy chọn; hữu ích để xác định phạm vi cho một tệp hoặc tập dữ liệu:
{{ $fromAI(‘filter’) || {} }}
Ví dụ mà tác nhân của bạn có thể vượt qua:
{“doc_id”:”1V-HrbpFgWKDonx8f-5dY_n7Ym3TxAw6″} // specific file {“dataset_id”: “acme-handbook”} // your own grouping {“mime”: “text/csv”} // metadata filter
Trả về trường : id, content, metadata, similarity, doc_id, chunk_index
(Đảm bảo chế độ xem/SQL của bạn trả về doc_idđể tác nhân có thể trích dẫn và lấy hàng.)
Nguồn nhúng : chọn Embeddings OpenAI2 (đầu nối chấm).
Nếu nút của bạn có nút chuyển đổi “Sử dụng hàm SQL tùy chỉnh” , hãy trỏ nó tới match_documents(query_embedding, match_count, filter).
2.3 Mô tả công cụ (siêu quan trọng)
Trong tab Công cụ của nút (hoặc “Tài liệu”/“Mô tả”), hãy dán nội dung tương tự như sau để tác nhân biết khi nào và cách sử dụng:
Tên: vector_search
Mô tả (cho tác nhân):
“Sử dụng công cụ này để tìm các đoạn văn liên quan từ cơ sở kiến thức.
Đối số:
•query (chuỗi, bắt buộc) — câu hỏi của người dùng hoặc nội dung cụ thể bạn cần tìm.
•top_k (số nguyên, tùy chọn, mặc định là 6) — số lượng khối cần trả về.
•filter (đối tượng, tùy chọn) — ràng buộc kết quả, ví dụ { “doc_id”: “<google_drive_id>” }: , { “dataset_id”: “acme-handbook” }, { “mime”: “text/csv” }.
Khi nào nên sử dụng: Bất cứ khi nào câu hỏi yêu cầu các dữ kiện không chắc chắn sẽ có trong bộ nhớ. Gọi công cụ này trước khi soạn câu trả lời cuối cùng, sau đó trích dẫn doc_idhoặc lưu tiêu đề từ siêu dữ liệu.”
Cách diễn đạt này cải thiện đáng kể việc sử dụng công cụ.
3) Kết nối Công cụ với Tác nhân
Vẽ đường Công cụ chấm bi từ Supabase Vector Store1 đến RAG AI Agent .
Giữ nguyên các kết nối chấm bi khác của bạn nữa:
Mô hình → Trò chuyện OpenAI
Bộ nhớ → Bộ nhớ trò chuyện Postgres
Các công cụ SQL bổ sung → Lấy nội dung tệp / Truy vấn hàng tài liệu (từ màu vàng)
Bây giờ tác nhân có thể quyết định:
“Tôi cần nền tảng” → vector_search
“Người dùng đã tham chiếu đến một tệp” → thêmfilter: { “doc_id”: “<id>” }
“Tôi cần toàn bộ văn bản PDF” → gọi công cụ Lấy nội dung tệp của bạn
“Tôi cần các hàng từ CSV” → gọi Truy vấn Hàng Tài liệu
4) Tùy chọn: Sử dụng cùng một nút để Chèn trong Xanh lam (thu thập)
Đường ống Blue của bạn đã chèn các khối, nhưng để hoàn thiện:
Thao tác: Chèn / Chèn lên
Văn bản để nhúng :
{{$json.chunk_text || $json.text || $json.content}}
Các cột bổ sung :
doc_id→{{$json.doc_id}}
chunk_index→{{$itemIndex}}
giữ lại bất kỳ thông tin nào metadatabạn muốn (tiêu đề, URL, mime, trang, bảng tính, v.v.)
Điều này giúp cho việc tìm kiếm và chèn sử dụng cùng một mô hình nhúng và bố cục bảng.
5) Kiểm tra sức khỏe nhanh
Sự tỉnh táo của SQL:
SELECT COUNT(*) FROM documents;
SELECT doc_id, COUNT(*) FROM documents GROUP BY 1 ORDER BY 2 DESC LIMIT 10;Tốc độ tỉnh táo (sau khi thêm chỉ số ivfflat):
EXPLAIN ANALYZE
SELECT id
FROM documents
ORDER BY embedding <-> (SELECT embedding FROM documents LIMIT 1)
LIMIT 5;
(Chỉ để đảm bảo toán tử vectơ và chỉ số hoạt động.)
6) Các vấn đề thường gặp và cách khắc phục
Không khớp kích thước
Triệu chứng: lỗi tìm kiếm/chèn đề cập đến độ dài vectơ.
Khắc phục: Mô hình phải khớp với DB: text-embedding-3-small⇔vector(1536)
RLS / quyền (Supabase)
Triệu chứng: tìm kiếm không trả về kết quả nào trong môi trường production, nhưng hoạt động cục bộ.
Khắc phục: gọi Postgres với người dùng có đặc quyền (điều bạn đang làm bây giờ) hoặc tạo chính sách RLS cho documents+ allow match_documents.
Không có doc_idtrong kết quả
Triệu chứng: tác nhân tìm thấy văn bản nhưng không thể trích dẫn hoặc lấy hàng.
Khắc phục: đảm bảo select/function của bạn trả về doc_idvà bạn điền vào trong quá trình nhập.
Sửa lỗi truy vấn chậm
: Tạo chỉ mục IVFFLAT ( vector_cosine_ops, chọn danh sách 100–200) và ANALYZE.
7) Những gì tác nhân của bạn “nhìn thấy” khi chạy
Công cụ này trả về một mảng các phần tốt nhất :
{
“id” : 12345,
“content” : “…đoạn văn bản ngắn…” ,
“metadata” : { “title” : “Báo cáo quý 2” , “page” : 3, “mime” : “application/pdf” },
“doc_id” : “1V-HrbpFgWKDonx8f-5dY_n7Ym3TxAw6” ,
“similarity” : 0.87,
“chunk_index” : 12
},
…
] Lời nhắc hệ thống (Màu vàng) của bạn sẽ yêu cầu mô hình trích dẫn bằng cách sử dụng metadata.title(nếu có) và/hoặc doc_id, và gọi các công cụ SQL của bạn nếu cần toàn văn hoặc hàng .
Khắc phục sự cố & Bài học kinh nghiệm
Lỗi 1 — Kết nối Supabase liên tục bị lỗi ( ENETUNREACH, thời gian chờ)
Triệu chứng
n8n Thông tin đăng nhập Postgres db.<project>.supabase.co:5432không thành công với ENETUNREACH … Local (::0).
Postman/web hoạt động, nhưng DNS phía máy chủ ưu tiên IPv6 và đường dẫn đến Supabase IPv6 không thể truy cập được.
Nguyên nhân gốc rễ là
Node.js đã giải quyết DNS theo hướng ưu tiên IPv6 trên máy chủ/mạng; IPv6 đi không thể đến được Supabase.
Tùy chọn sửa lỗi (chúng tôi sử dụng kết hợp):
Ưu tiên IPv4 trong Node
Docker / docker-compose:
services: n8n: environment: – NODE_OPTIONS=–dns-result-order=ipv4first
Kim loại trần / PM2 / systemd:
export NODE_OPTIONS=”–dns-result-order=ipv4first” # then start n8n normally
2. Đường hầm SSH qua bất kỳ VPS nào chỉ có IPv4
Quay một giọt Ubuntu nhỏ (DigitalOcean, Lightsail…)
Trong n8n Postgres credential → SSH Tunnel: ON
Máy chủ SSH:<your VPS public IP>
Cảng:22
Người dùng: ubuntu(hoặc root)
Xác thực: dán khóa riêng tư hoặc sử dụng mật khẩu.
n8n hiện kết nối với Supabase thông qua VPS (có IPv4).
3. Sự lành mạnh của tường lửa
Đảm bảo luồng dữ liệu ra tcp/5432được phép từ nơi n8n chạy (một số máy chủ chặn luồng dữ liệu này).
Sau khi buộc IPv4, kết nối được kiểm tra ngay lập tức chuyển sang màu xanh lá cây.
Lỗi 2 — pgvectorkhông có trên Postgres 12
Triệu chứng
không thể mở tệp điều khiển tiện ích mở rộng “/usr/share/postgresql/12/extension/vector.control”
Nguyên nhân gốc rễ khiến
Ubuntu 20.04 với Postgres 12 không pgvectorkhả dụng.
Đã sửa (chúng tôi đã nâng cấp lên PG16 + pgvector)
Thêm kho lưu trữ PGDG chính thức của PostgreSQL (nếu lần đầu bạn gặp lỗi 404, hãy sử dụng tập lệnh trợ giúp của họ):
sudo apt update sudo apt install -y ca-certificates curl gnupg postgresql-common sudo /usr/share/postgresql-common/pgdg/apt.postgresql.org.sh sudo apt update
2. Cài đặt PG16 + pgvector:
sudo apt install -y postgresql-16 postgresql-client-16 postgresql-16-pgvector
3. Nâng cấp cụm của bạn (12 → 16):
sudo pg_upgradecluster 12 main sudo pg_ctlcluster 16 main start sudo pg_dropcluster 12 main # only after verifying the 16 cluster works
4. Tạo phần mở rộng một lần cho mỗi cơ sở dữ liệu (dưới dạng siêu người dùng):
sudo -u postgres psql -d rag -c “CREATE EXTENSION IF NOT EXISTS vector;” sudo -u postgres psql -d n8n -c “CREATE EXTENSION IF NOT EXISTS vector;” \dx # verify ‘vector’ is listed
Những thay đổi: nút “Tạo bảng tài liệu & chức năng khớp” chuyển sang màu xanh vì vectorloại đó đã tồn tại.
Lỗi 3 — “quyền tạo tiện ích mở rộng bị từ chối vector”
Triệu chứng
Khi chạy Red-part DDL từ n8n, bạn thấy:
permission denied to create extension “vector” Must be superuser to create this extension.
Nguyên nhân gốc rễ
Việc tạo tiện ích mở rộng yêu cầu siêu người dùng .
Sửa chữa
Tạo phần mở rộng theo cách thủ công một lần ( sudo -u postgres psql … CREATE EXTENSION vector;).
Chạy lại nút Red của bạn; bây giờ nó chỉ tạo bảng/hàm (có thể dùng cho người dùng không phải siêu cấp).
Lỗi 4 — Các đoạn mã mồ côi, thao tác xóa không thành công, trích dẫn tệp sai ( doc_idlỗi)
Triệu chứng
“Xóa hàng tài liệu cũ” / “Xóa hàng dữ liệu cũ” không khớp với kết quả nào.
Kết quả tìm kiếm đôi khi trích dẫn sai tệp hoặc không thể nối các hàng CSV.
Các bảng có nhiều phần không có liên kết đáng tin cậy trở lại tệp của chúng.
Nguyên nhân gốc rễ
doc_id có thể là giá trị null/không được điền khi chèn.
Không có doc_id:
documents↔ document_metadatatham gia ngắt quãng.
documents↔ document_rowstham gia ngắt quãng.
Dọn dẹp theo tệp không khớp với bất kỳ thứ gì.
Sửa chữa (những gì chúng tôi đã vận chuyển)
Xanh lam → Đặt ID tệp
file_id = {{$json.id || $json.fileId}}
2. Màu xanh lam → Đặt (ngay trước khi chèn vectơ)
doc_id = {{$json.file_id}}
3. Chèn vectơ → Tùy chọn → Cột bổ sung
doc_id→{{$json.doc_id}}
(tùy chọn) chunk_index→{{$itemIndex}}
4. Các nút dọn dẹp ( Delete Old Doc Rows/ Delete Old Data Rows):
Lọc theo doc_id, không phải theo tên tệp hoặc tập dữ liệu.
Kết quả
Mỗi khối/hàng đều liên kết đến tệp nguồn của nó; các lệnh xóa đều chính xác; các trích dẫn cũng chính xác.
Lỗi 5 — Bộ nhớ trò chuyện Postgres n8n: “giá trị đầu vào có 3 khóa… hãy chỉ định một khóa đầu vào”
Triệu chứng
Lỗi nút bộ nhớ: nó mong đợi một khóa duy nhất có ID phiên.
Sửa chữa
Trong nút Bộ nhớ → ID phiên → Xác định bên dưới
Chìa khóa :chatInput
Trong mục Chỉnh sửa trường (Màu vàng) , hãy thiết lập:
chatInput = {{$json.session_id || $json.user_id || ‘default-session’}}
Bao gồm các trường nhập liệu khác : TẮT
(Vì vậy, nút bộ nhớ chỉ nhận được một khóa.)
Lỗi 6 — Webhook 403 “Dữ liệu ủy quyền không đúng”
Triệu chứng
Người đưa thư gọi điện /webhook-test/asktrả lời 403.
Nguyên nhân gốc rễ
Thiếu tiêu đề khóa API mà nút Webhook của bạn mong đợi.
Sửa chữa
n8n Header Xác thực:
Tên :x-api-key
Giá trị : (một bí mật ngẫu nhiên dài)
2. Trong Postman → Tiêu đề :
x-api-key: <the-same-secret>
3. Nội dung (JSON), ví dụ:
{ “message”: “What is in sample.csv? List items and amounts”, “session_id”: “postman-001”, “user_id”: “postman” }
Những gì tôi đã học được
Đầu tiên, việc nối đất là một vấn đề về kỹ thuật dữ liệu.
RAG bao gồm 80% là nhập liệu và khóa. Trường duy nhất mở khóa mọi thứ là doc_id. Với nó, việc kết hợp văn bản ↔ hàng ↔ siêu dữ liệu và thực hiện bảo trì theo từng tệp trở nên đơn giản.
Nâng cấp sớm nếu bạn cần tìm kiếm vector.
Đừng đấu tranh với PG12; hãy chuyển sang PG16 + pgvector để tiết kiệm thời gian.
Hãy làm cho các công cụ của tác nhân trở nên rõ ràng.
Mô tả công cụ rõ ràng (đối số, thời điểm sử dụng, cách lọc) sẽ cải thiện đáng kể việc lựa chọn công cụ và giảm ảo giác.
Ưu tiên IPv4 (hoặc đường hầm) trong các mạng hỗn hợp.
Mã phía máy chủ âm thầm ưu tiên IPv6 sẽ khiến bạn ngạc nhiên.
Kiểm tra như con người + như máy móc.
Con người: Người đưa thư → Webhook (403, tải trọng, tiêu đề).
Máy: Kiểm tra khói SQL, \dx, COUNT(*), GROUP BY doc_id, chỉ mục IVFFLAT.
Phụ lục — SQL tiện dụng
Đếm và liên kết
SELECT COUNT(*) FROM documents;
SELECT doc_id, COUNT(*) FROM documents GROUP BY 1 ORDER BY 2 DESC LIMIT 10;
SELECT COUNT(*) FROM document_rows; — for CSV/XLSX
Chỉ số (tăng tốc)
CREATE INDEX IF NOT EXISTS documents_embedding_idx
ON documents USING ivfflat (embedding vector_cosine_ops) WITH (lists = 100);
ANALYZE documents;
Tìm kiếm hợp lý (sẽ trả về nhanh chóng sau khi lập chỉ mục)
EXPLAIN ANALYZE
SELECT id
FROM documents
ORDER BY embedding <-> (SELECT embedding FROM documents LIMIT 1)
LIMIT 5;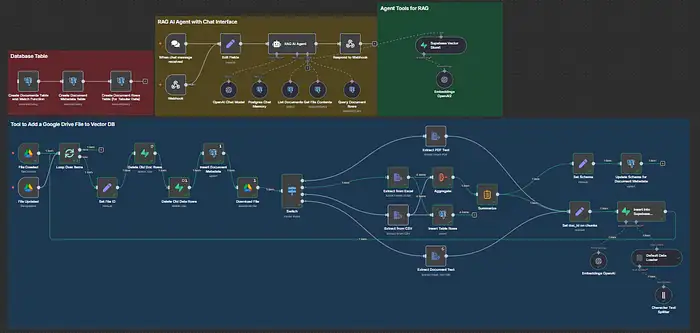
Tôi bắt đầu xây dựng dự án này với một chatbot rời rạc và một thư mục đầy những tập tin lộn xộn. Cuối cùng, nó trở thành một hệ thống RAG chuyên nghiệp , lập kế hoạch, tìm kiếm và trả lời bằng biên lai. Trong quá trình đó, tôi học được rằng điều kỳ diệu không nằm ở một mô hình hào nhoáng – mà nằm ở những quyết định nhỏ nhưng vững chắc:
Hãy giữ gìn doc_idsự thiêng liêng. Đó là sợi chỉ kết nối mọi thứ lại với nguồn gốc của nó.
Chọn đúng nguyên mẫu. PG16 + pgvector, bảng sạch, công cụ rõ ràng.
Tự động hóa quá trình kết dính. n8n biến một tập lệnh dễ hỏng thành một hệ thống đáng tin cậy mà bạn có thể xem, kiểm tra và tin tưởng.
Nếu bạn làm theo hướng dẫn này, bạn sẽ không chỉ nhận được bản demo — bạn sẽ có được nền tảng để phát triển: nhiều loại tệp hơn, công cụ tốt hơn, bộ nhớ phong phú hơn, người dùng thực sự. Và khi có sự cố (sẽ xảy ra…), bạn sẽ có cẩm nang để khắc phục nhanh chóng.
Từ n8n đến Python: Xây dựng dịch vụ RAG Agentic với Flask, Postgres/pgvector và Google Drive
Bài viết liên quan: